本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/1361.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

PHP-Mysql好运图书管理系统--【白嫖项目】
强撸项目系列总目录在000集
PHP要怎么学–【思维导图知识范围】 文章目录 本系列校训本项目使用技术 首页必要的项目知识ThinkPHP的MVCThinkTemplateThinkPHP 6和ThinkPHP 5 phpStudy 设置导数据库前台展示页面后台的管理界面数据库表结构项目目录如图:代码部分&a…

Zabbix分布式监控快速入门
目录 1 Zabbix简介1.1 软件架构1.2 版本选择1.3 功能特性 2 安装与部署2.1 时间同步需求2.2 下载仓库官方源2.3 Zabbix-Server服务端的安装2.3.1 安装MySQL2.3.1.1 创建Zabbix数据库2.3.1.2 导入Zabbix库的数据文件 2.3.2 配置zabbix_server.conf2.3.3 开启Zabbix-Server服务2.…

【Vue】在el-table的el-table-column中,如何控制单行、单列、以及根据内容单独设置样式。例如:修改文字颜色、背景颜色
用cell-style表属性来实现。在官网中是这样表述这个属性的。 在el-table中用v-bind绑定此属性。(v-bind的简写是:) <el-table:data"options":cell-style"cell"><el-table-column prop"id" label"…

【能量管理系统( EMS )】基于粒子群算法对光伏、蓄电池等分布式能源DG进行规模优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…
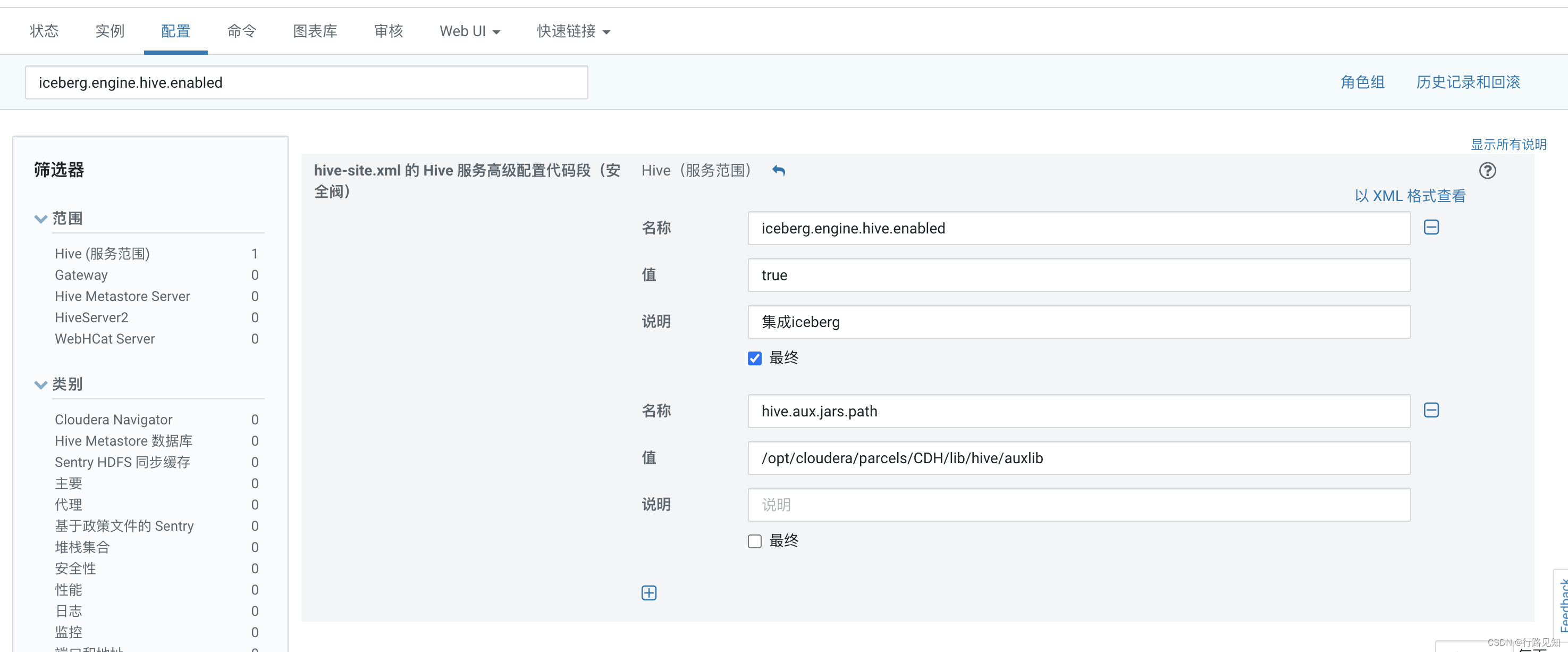
CHD6.2.1集群 Hive开启Iceberg
下载jar包
https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-hive-runtime/1.0.0/iceberg-hive-runtime-1.0.0.jar 存放在/opt/cloudera/parcels/CDH/lib/hive/auxlib/ CDH集群修改hive配置 选择xml格式 粘贴即可
<property><name>iceberg.engine.hi…

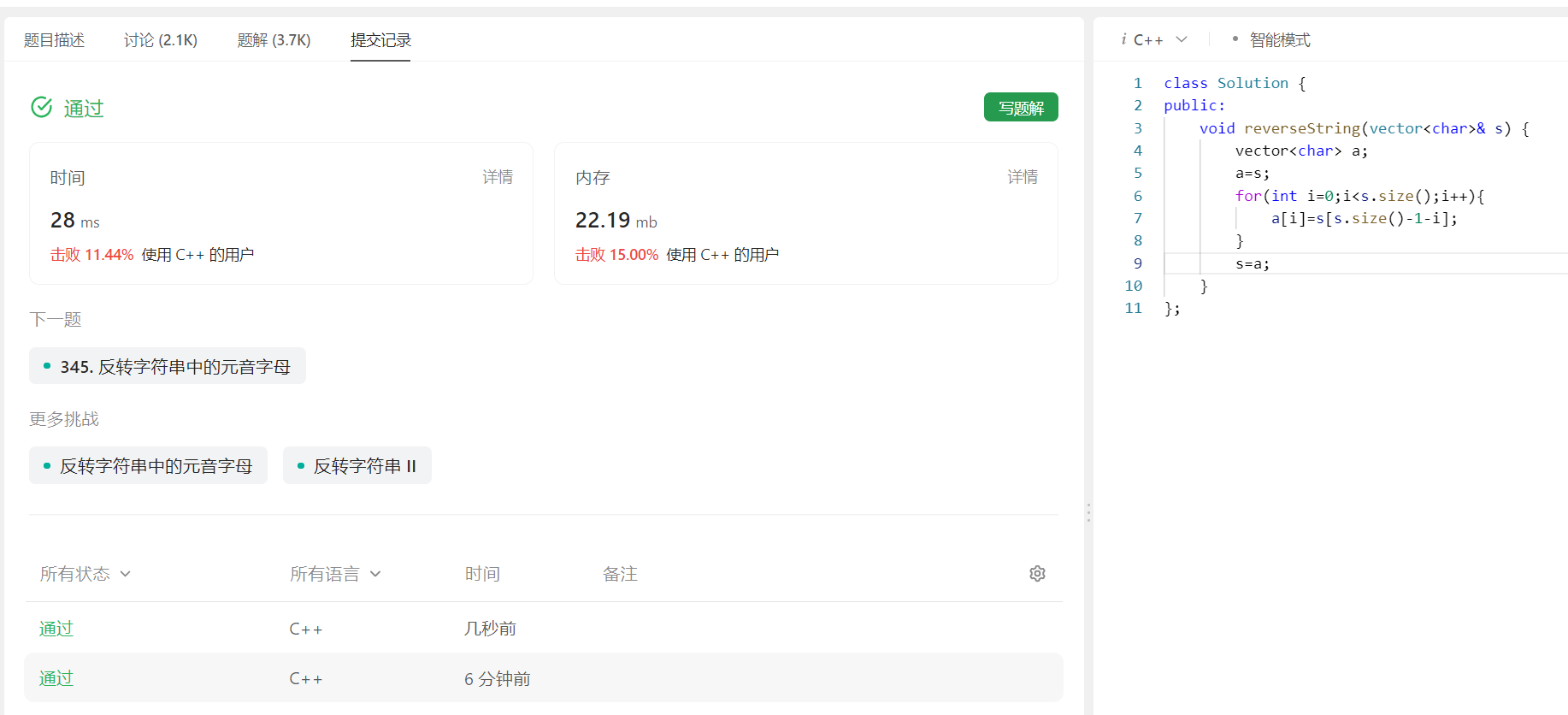
leetcode每日一题Day2——344. 反转字符串
✨博主:命运之光 🦄专栏:算法修炼之练气篇(C\C版) 🍓专栏:算法修炼之筑基篇(C\C版) 🐳专栏:算法修炼之练气篇(Python版) …

矩阵中的路径(JS)
矩阵中的路径
题目
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是…
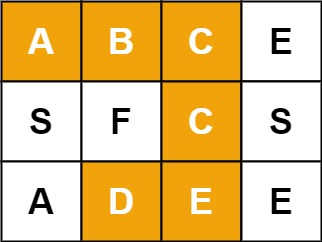
单网卡实现 双IP 双网段(内外网)同时运行
前提是内外网是同一网线连接(双网线双网卡的具体可以自己搜索下。理论上都设置静态IP后把外网跃点设置小,内网跃点设置大,关闭自动跃点设置同一个接口跃点数,在通过命令提示符添加内网网址走内网网关就可以了)。 需要使…
电脑卡顿反应慢怎么处理?提升反应速度的方法
电脑卡顿反应慢是很常见的问题,然而,我们可以采取一些方法来处理这个问题,帮助大家提升电脑反应速度。
一、提升电脑反应速度的方法
当电脑运行顺畅时,我们的工作体验也会更加愉悦。然而,如果电脑出现卡顿反应慢的…
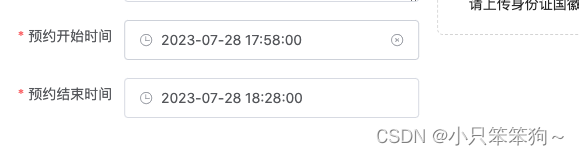
<el-date-picker>组件选择开始时间,结束时间自动延长30min
背景:选择开始时间,结束时间自动增加30分钟,结束时间也可重新选择,如图: <el-form-item label"预约开始时间" prop"value1"><el-date-pickersize"large"v-model"ruleForm…

【Golang 接口自动化02】使用标准库net/http发送Post请求
目录
写在前面
发送Post请求
示例代码
源码分析
Post请求参数解析
响应数据解析
验证
发送Json/XMl
Json请求示例代码
xml请求示例代码
总结
资料获取方法 写在前面
上一篇我们介绍了使用 net/http 发送get请求,因为考虑到篇幅问题,把Post单…

三子棋(超详解+完整码源)
三子棋 前言一,游戏规则二,所需文件三,创建菜单四,游戏核心内容实现1.棋盘初始化1.棋盘展示3.玩家下棋4.电脑下棋5.游戏胜负判断6.game()函数内部具体实现 四,游戏运行实操 前言 C语言实现三子棋…
Flutter Widget Life Cycle 组件生命周期
Flutter Widget Life Cycle 组件生命周期 视频 前言 了解 widget 生命周期,对我们开发组件还是很重要的。 今天会把无状态、有状态组件的几个生命周期函数一起过下。 原文 https://ducafecat.com/blog/flutter-widget-life-cycle 参考 https://api.flutter.dev/f…

【Linux】更换jdk版本
目录 一、前言二、查看jdk版本号1、项目中的版本号(pom.xml)2、服务器中的版本号 三、更换jdk版本1、创建java文件夹2、下载并解压JDK安装包①、下载jdk安装包②、移动到创建好的/usr/local/java路径下③、解压jdk安装包 四、删除原来的jdk版本1、删除原…

自建纯内网iot平台服务,软硬件服务器全栈实践
基于以下几个考虑,自制硬件设备,mqtt内网服务器。 1.米家app不稳定,逻辑在云端或xiaomi中枢网关只支持少部分在本地计算。 2.监控homeassistant官方服务有大量数据交互。可能与hass安装小米账户有关。 3.硬件:原理图,l…

oracle,获取每日24*60,所有分钟数
前言: 为规范用户的时间录入,因此我们采用下拉的方式,让用户选择需要的时间,因此我们需要将一天24小时的时间拆分为类似00:00,00:01...23:00,23:01,23:59。因此我们需要生成24*601440行的下拉复选值。具体效果如下图所示。 思路 1…