本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/138256.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

Android Studio插件版本与Gradle 版本对应关系
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。 目录 一、导读二、概览三、Gradle各版本对应关系3.1 Gradle 版…

26663-2011 大型液压安全联轴器 课堂随笔
声明
本文是学习GB-T 26663-2011 大型液压安全联轴器. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们
1 范围
本标准规定了大型液压安全联轴器的分类、技术要求、试验方法及检验规则等。
本标准适用于联接两同轴线的传动轴系,可起到限制…
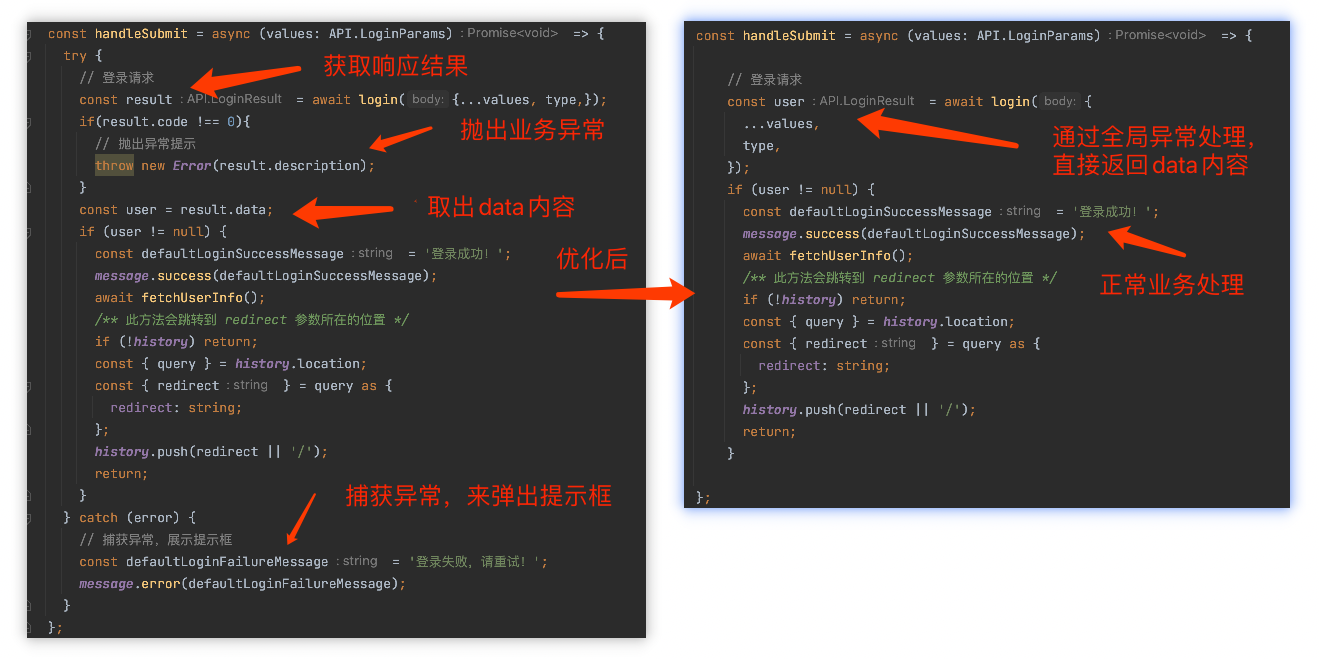
【AntDesign】封装全局异常处理-全局拦截器
[toc]
场景 本文前端用的是阿里的Ant-Design框架,其他框架也有全局拦截器,思路是相同,具体实现自行百度下吧 因为每次都需要调接口,都需要单独处理异常情况(code !0),因此前端需要对后端返回的…
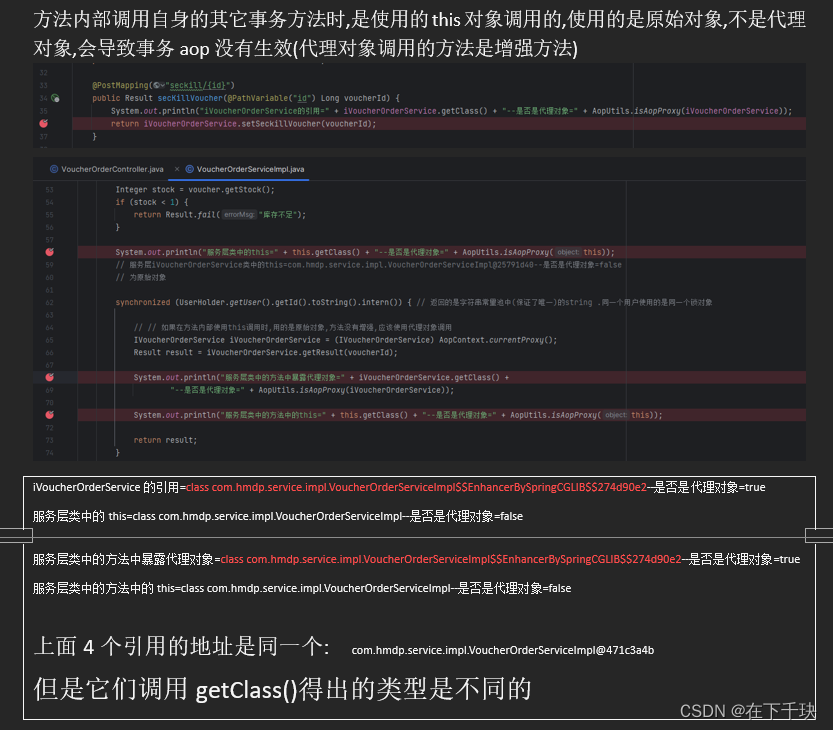
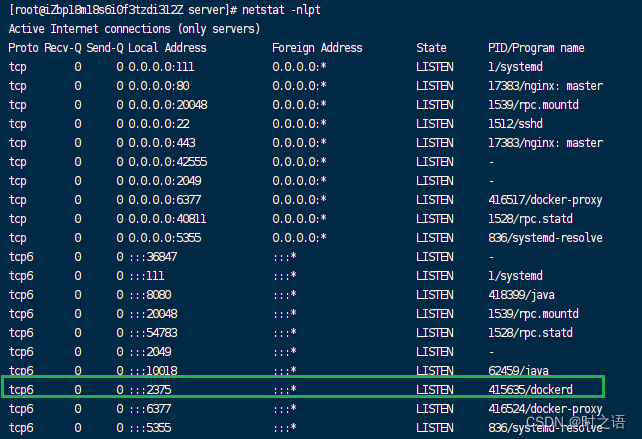
解决Linux服务器中docker访问报127.0.0.1:2375拒绝连接 (Connection refused)的问题
解决问题: org.apache.hc.client5.http.HttpHostConnectException: Connect to http://127.0.0.1:2375 [/127.0.0.1] failed: 拒绝连接 (Connection refused) 解决思路: 在Linux服务器中,Docker是远程访问的,因此需要开放2375端口…
Java 基于 SpringBoot 的在线学习平台
1 简介
基于SpringBoot的Java学习平台,通过这个系统能够满足学习信息的管理及学生和教师的学习管理功能。系统的主要功能包括首页,个人中心,学生管理,教师管理,课程信息管理,类型管理,作业信息…
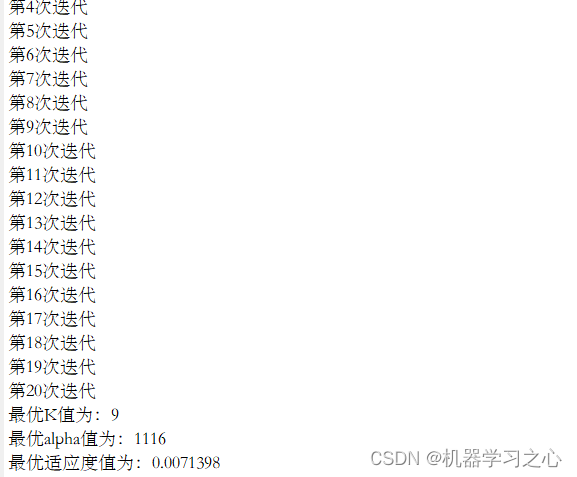
时序分解 | Matlab实现SSA-VMD麻雀算法优化变分模态分解时间序列信号分解
时序分解 | Matlab实现SSA-VMD麻雀算法优化变分模态分解时间序列信号分解 目录 时序分解 | Matlab实现SSA-VMD麻雀算法优化变分模态分解时间序列信号分解效果一览基本介绍程序设计参考资料 效果一览 基本介绍 SSA-VMD麻雀搜索算法SSA优化VMD变分模态分解 可直接运行 分解效果好…

华为云云耀云服务器L实例评测 | 实例评测使用之体验评测:华为云云耀云服务器安全加固/防范黑客攻击
华为云云耀云服务器L实例评测 | 实例评测使用之体验评测:华为云云耀云服务器安全加固/防范黑客攻击 介绍华为云云耀云服务器 华为云云耀云服务器 (目前已经全新升级为 华为云云耀云服务器L实例) 华为云云耀云服务器是什么华为云云…
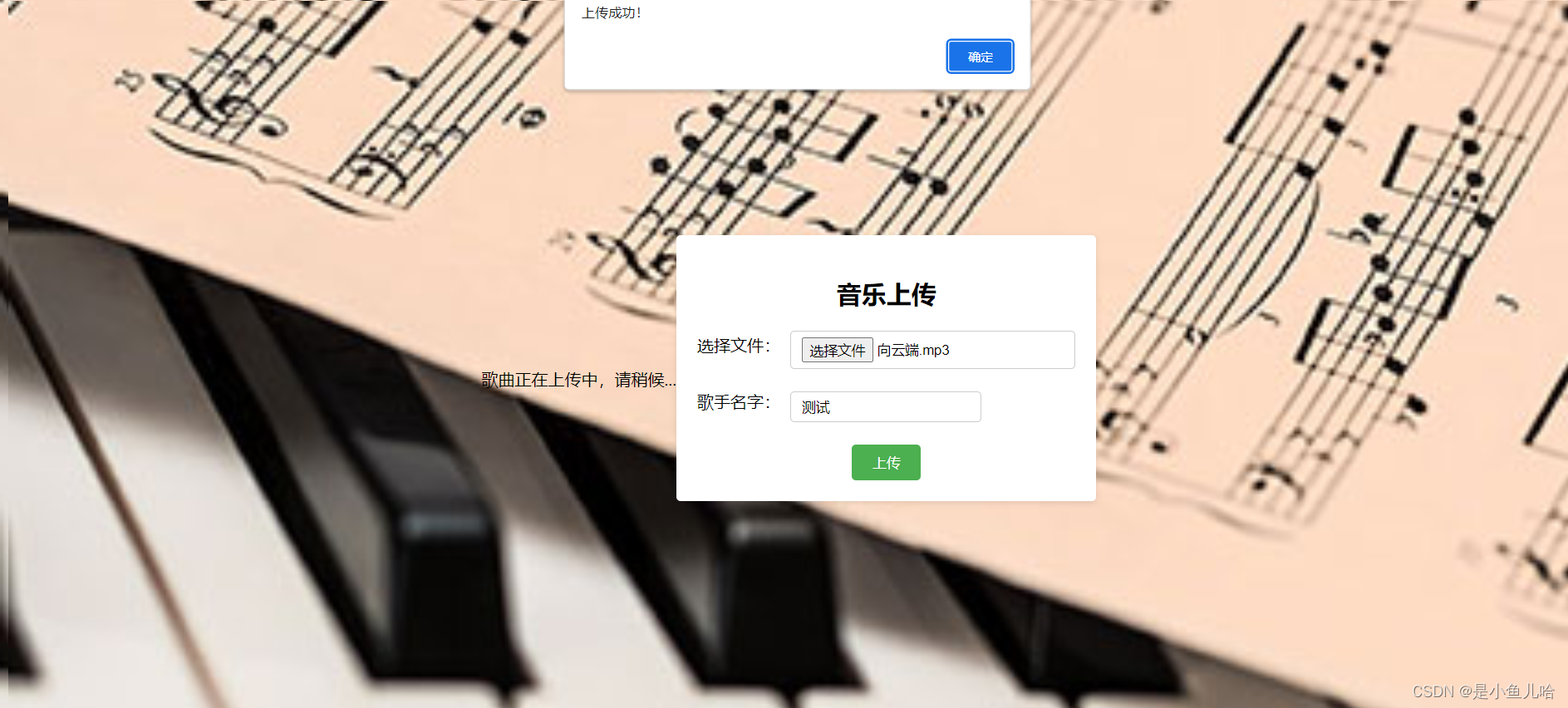
【项目】在线音乐播放器测试报告
目录 项目背景
项目功能
测试计划
功能测试
登录页面的测试
测试用例
测试结果
注册页面的测试
测试用例
测试结果
音乐列表页面的测试
测试用例
测试结果
出现的bug
搜索功能的bug
问题解决
删除功能的bug
问题解决
喜欢列表页面的测试
测试用例
测试结果…

stc8H驱动并控制三相无刷电机综合项目技术资料综合篇
stc8H驱动并控制三相无刷电机综合项目技术资料综合篇 🌿相关项目介绍《基于stc8H驱动三相无刷电机开源项目技术专题概要》 🔨停机状态,才能进入设置状态,可以设置调速模式,以及转动方向。 ✨所有的功能基本已经完成调试,目前所想到的功能基本已经都添加和实现。引脚利…

python进制转换
"""
基数:有几个数
0b 2进制: 0、1 基数是:2
0o 8进制: 0、1、2、3、4、5、6、7 基数是:8
0d 10进制: 0到9 基数是:10
0x 16进制: 0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F 基数是:16十进制转二进制: bin()
十进制转八进…
安卓玩机-----给app加注册码 app加弹窗 云注入弹窗
在对接很多工作室业务中有些客户需要在他们自带的有些app中加注册码或者验证码的需求。其实操作起来也很简单。很多反编译软件有自带的注入功能。例如注入弹窗。这个是需要对应的注册码来启动应用。而且是随机id。重新安装app后需要重新注册才可以继续使用,原则上可…
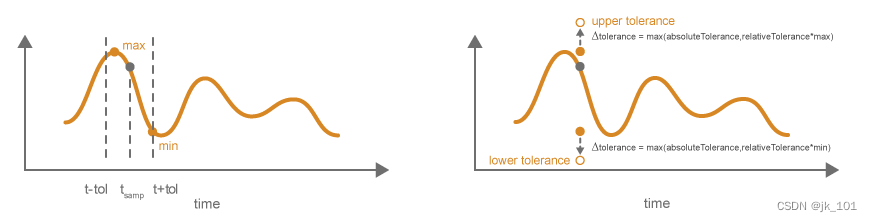
仿真数据检查器如何比较数据
可以定制仿真数据检查器比较过程,以多种方式满足您的需求。在比较各运行时,仿真数据检查器会执行以下操作: 根据对齐设置,对齐基线运行和比较项运行中的信号对组。 仿真数据检查器不会比较无法对齐的信号。 根据指定的同步方法同…
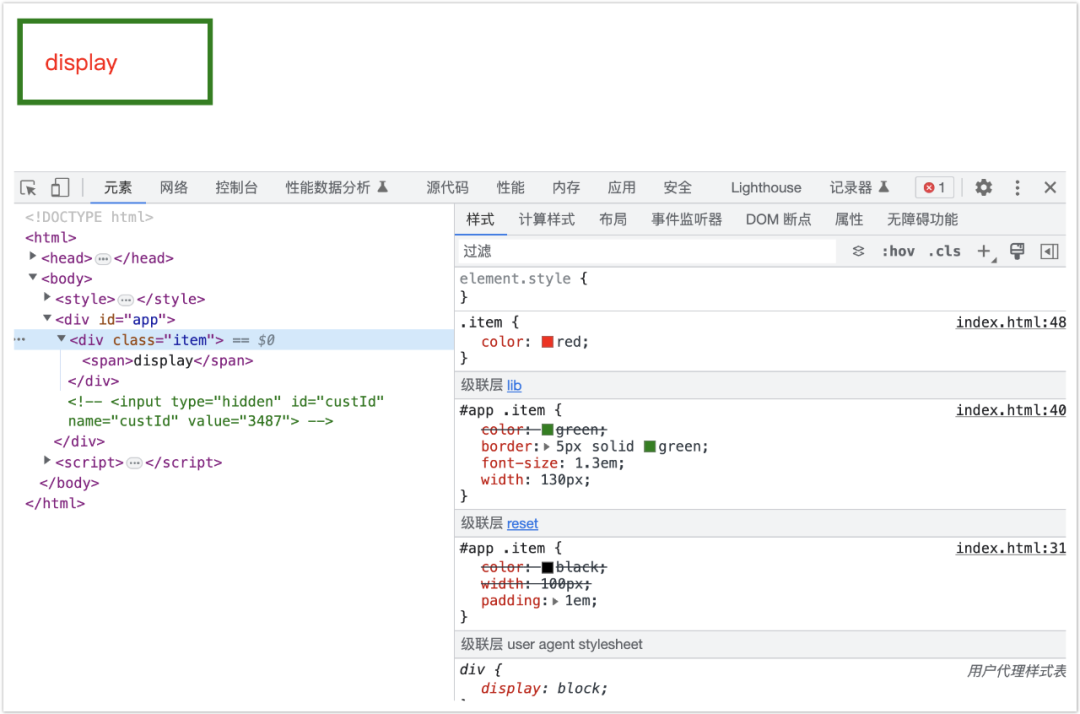
前端开发如何更好的避免样式冲突?级联层(CSS@layer)
本文主要讲述了CSS中的级联层(CSSlayer),讨论了级联以及级联层的创建、嵌套、排序和浏览器支持情况。级联层可以用于避免样式冲突,提高代码可读性和可维护性。
一、什么是级联层(Cascade Layers)?
1.1 级联层的官方定…
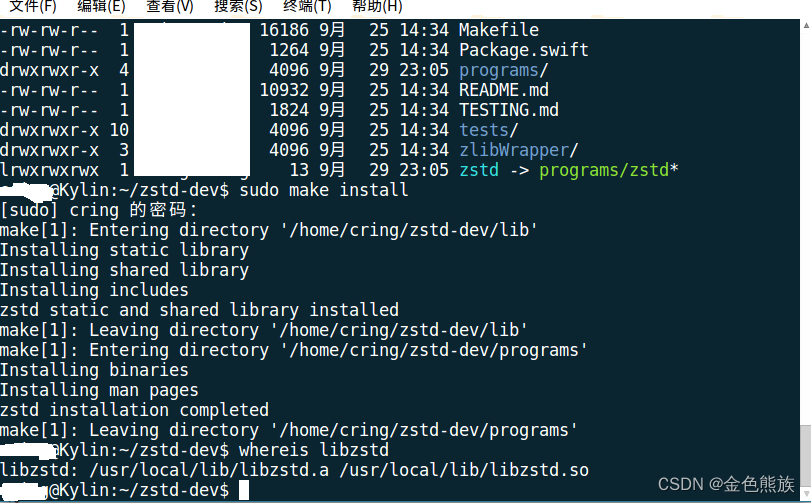
源码编译安装zstd
目录
1 下载源码https://github.com/facebook/zstd
2 解压
3 在解压后的目录里输入make
4 sudo make install 安装完毕
5 输入whereis zstd 检查安装结果 1 下载源码https://github.com/facebook/zstd
2 解压
3 在解压后的目录里输入make
4 sudo make install 安装完毕…

【2023保研】双非上岸东南网安
个人情况
学校:henu 专业:信息安全 排名:1/66 英语:六级500 竞赛:蓝桥杯PB国一,ISCC国一,密码数学挑战赛国三,还有其他一些省级水奖 论文:一篇EI在投(三作通…
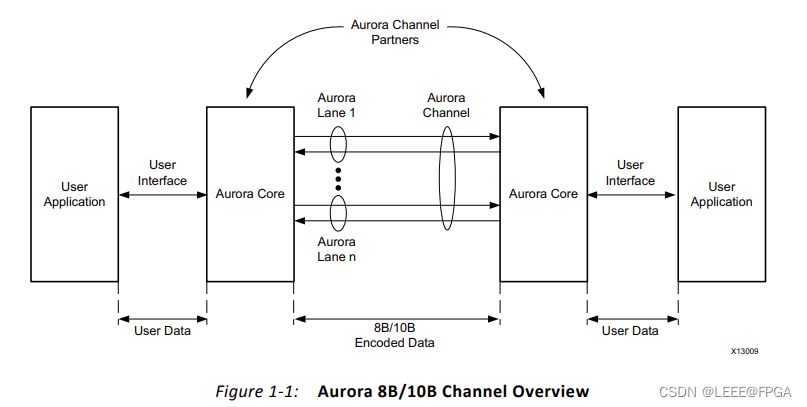
【Aurora 8B/10B IP(1)--初步了解】
Aurora 8B/10B IP(1)–初步了解
1 Aurora 8b/10b IP的基本状态:
•通用数据通道吞吐量范围从480 Mb/s到84.48 Gb/s
•支持多达16个连续粘合7GTX/GTH系列、UltraScale™ GTH或UltraScale+™ GTH收发器和4绑定GTP收发器
•Aurora 8B/10B协议规范v2.3顺从的
•资源成本低(请参…

python:bottle + eel 模仿 mdict 查英汉词典
Eel 是一个轻量的 Python 库,用于制作简单的类似于离线 HTML/JS GUI 应用程序,并具有对 Python 功能和库的完全访问权限。
Eel 托管一个本地 Web 服务器,允许您使用 Python 注释函数(annotate functions),…
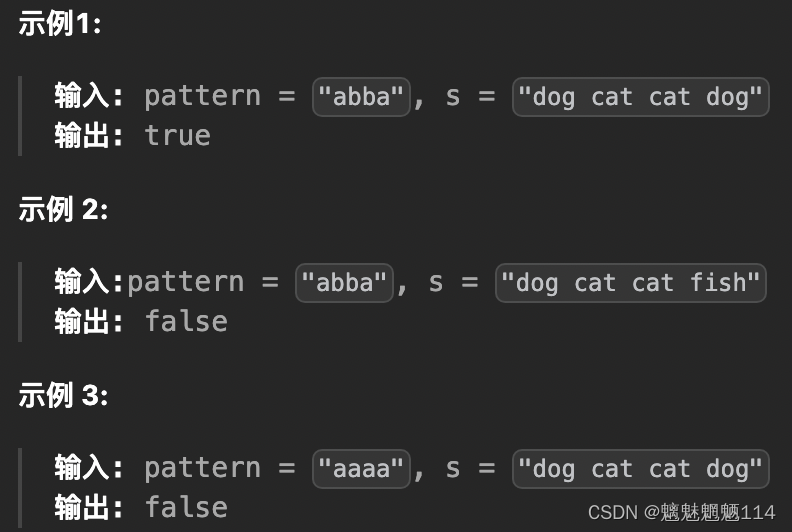
Leetcode290. 单词规律
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。 这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。 解题思路:哈希
力扣(LeetCode&…