本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/138293.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
Elastic SQL 输入:数据库指标可观测性的通用解决方案
作者:Lalit Satapathy, Ishleen Kaur, Muthukumar Paramasivam Elastic SQL 输入(metricbeat 模块和输入包)允许用户以灵活的方式对许多支持的数据库执行 SQL 查询,并将结果指标提取到 Elasticsearch。 本博客深入探讨了通用 SQL …
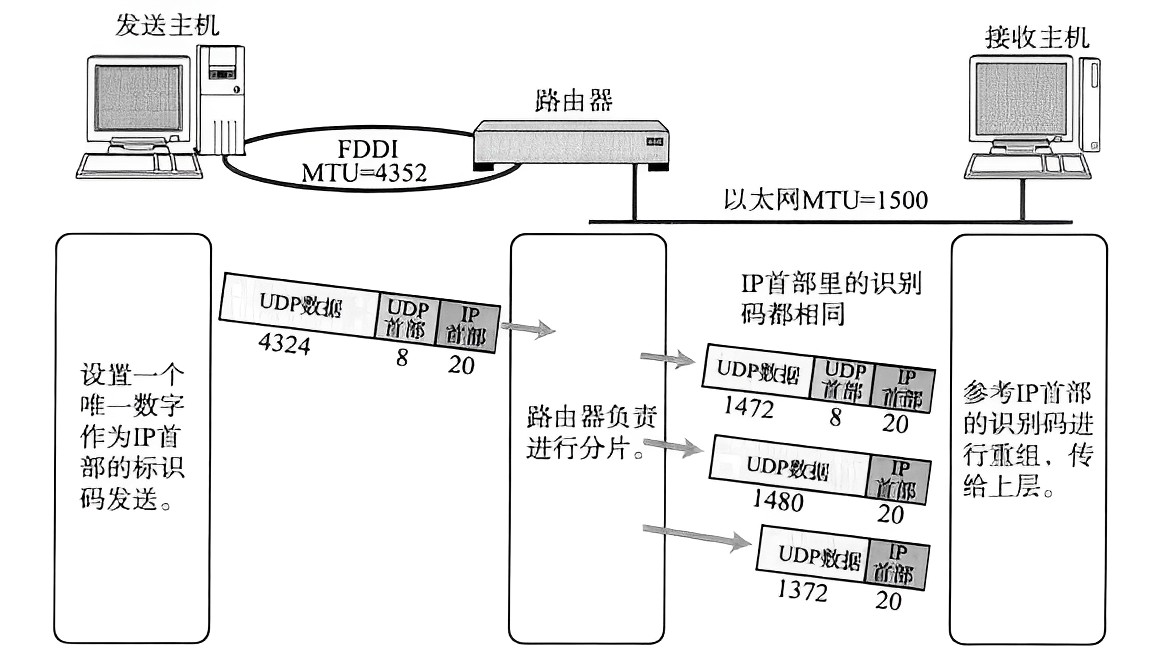
数据链路层 MTU 对 IP 协议的影响
在介绍主要内容之前,我们先来了解一下数据链路层中的"以太网" 。
“以太网”不是一种具体的网络,而是一种技术标准;既包含了数据链路层的内容,也包含了一些物理层的内容。
下面我们再来了解一下以太网数据帧ÿ…

Transformers.js v2.6 现已发布
🤯 新增了 14 种架构 在这次发布中,我们添加了大量的新架构:BLOOM、MPT、BeiT、CamemBERT、CodeLlama、GPT NeoX、GPT-J、HerBERT、mBART、mBART-50、OPT、ResNet、WavLM 和 XLM。这将支持架构的总数提升到了 46 个!以下是一些示例…
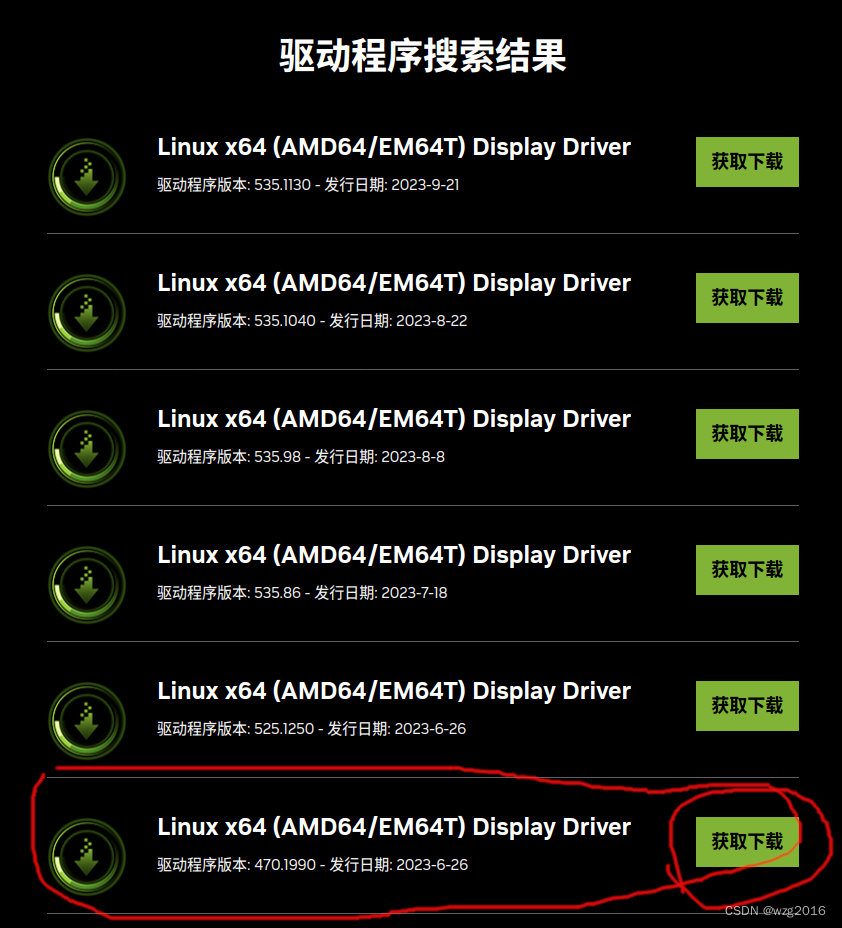
ubuntu20安装nvidia驱动
1. 查看显卡型号
lspci | grep -i nvidia
我的输出:
01:00.0 VGA compatible controller: NVIDIA Corporation GP104 [GeForce GTX 1080] (rev a1)
01:00.1 Audio device: NVIDIA Corporation GP104 High Definition Audio Controller (rev a1)
07:00.0 VGA comp…
stable diffusion模型评价框架
GhostReview:全球第一套AI绘画ckpt评测框架代码 - 知乎大家好,我是_GhostInShell_,是全球AI绘画模型网站Civitai的All Time Highest Rated (全球历史最高评价) 第二名的GhostMix的作者。在上一篇文章,我主要探讨自己关于ckpt的发展方向的观点…

测试用例的编写(面试常问)
作者:爱塔居 专栏:软件测试 作者简介:不断总结,才能变得更好~踩过的坑,不能再踩~ 文章简介:常见的几个测试用例。 一、淘宝购物车 二、登录页面 三、三角形测试用例
abc结果346普通三角形333等边三角形334…

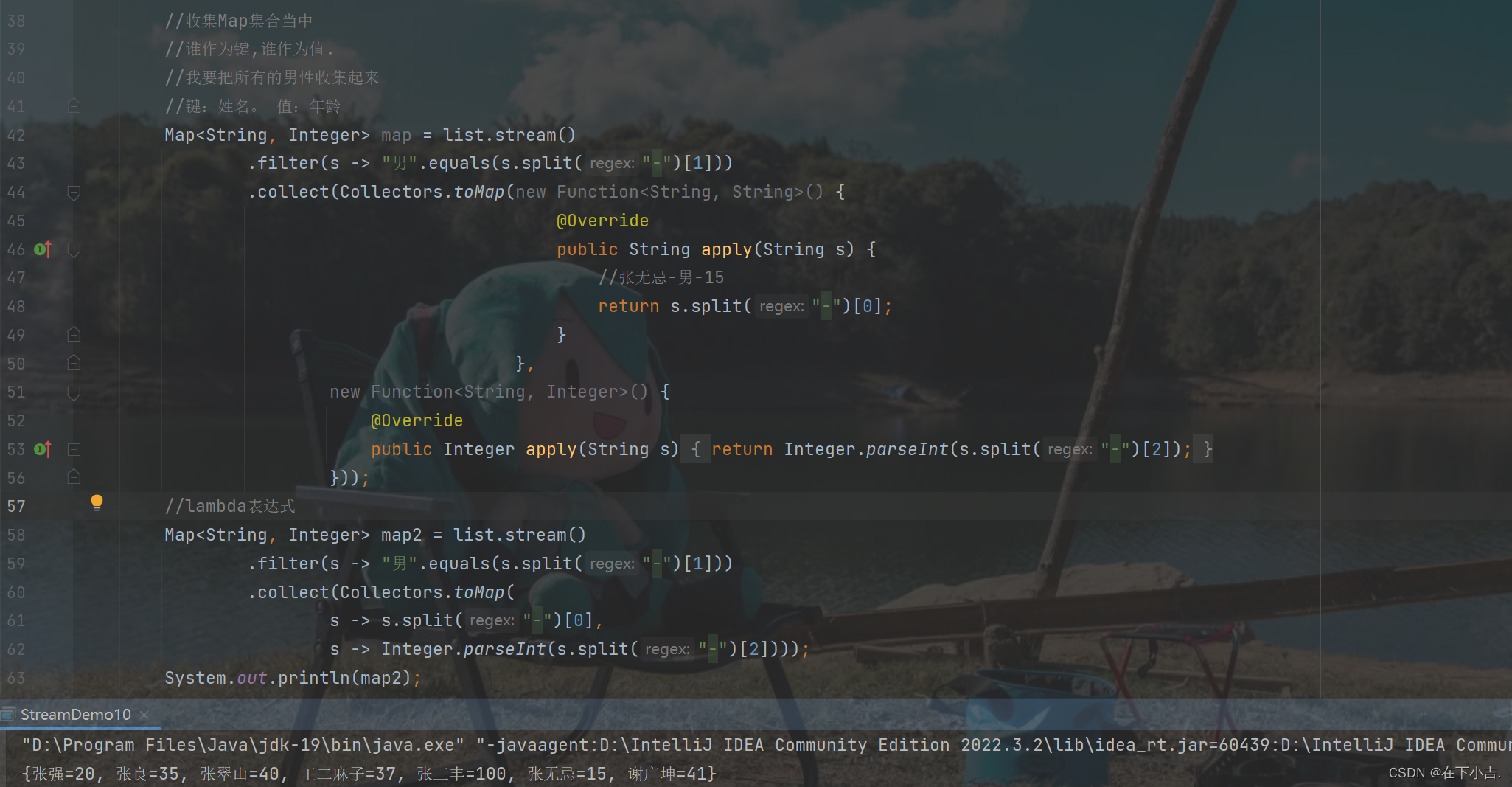
【从入门到起飞】JavaSE—Stream流
🎊专栏【JavaSE】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【如愿】 🥰欢迎并且感谢大家指出我的问题 文章目录 🍔Stream流的作用🍔Stream流的使用步骤🎄获取Strea…

Android Shape设置背景
设置背景时,经常这样 android:background“drawable/xxx” 。如果是纯色图片,可以考虑用 shape 替代。
shape 相比图片,减少资源占用,缩减APK体积。
开始使用。
<?xml version"1.0" encoding"utf-8"?…

100行 python实现Android与windows局域网文件夹同步
编程解决一切烦恼
Obsidian搭建个人笔记
最近在使用Obsidian搭建个人云笔记 尽管我使用腾讯云COS图床gitee实现了云备份,但是在Android上使的Obsidian备份有点麻烦。还好我主要是在电脑端做笔记,手机只是作为阅读工具。
所以,我写一个局域…
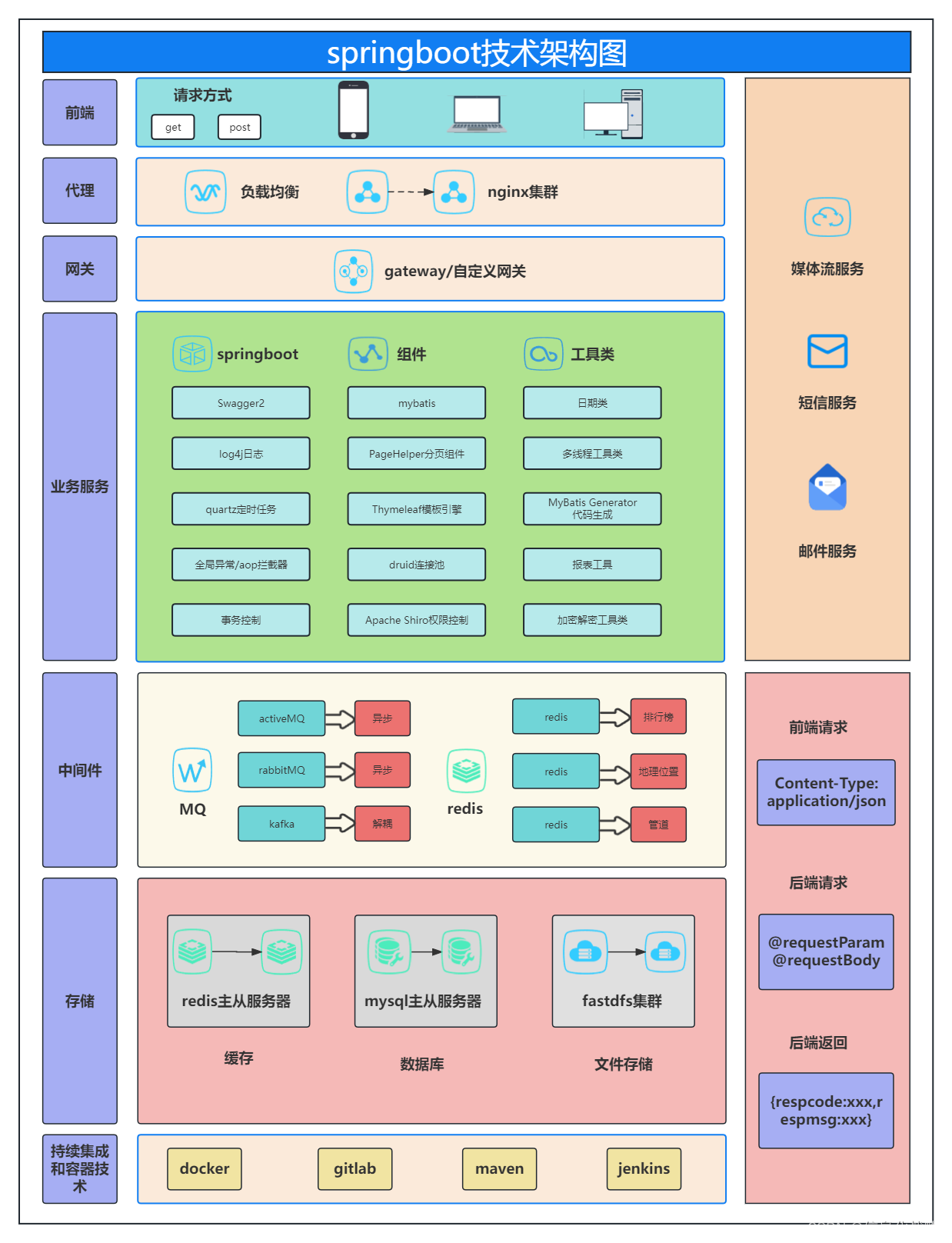
Spring Boot 技术架构图(InsCode AI 创作助手辅助)
Spring Boot 技术架构是一种用于构建现代应用程序的框架,它可以与各种前端、代理、网关、业务服务、中间件、存储、持续集成和容器服务集成在一起,以创建功能强大的应用程序。 源文件下载链接!!!!ÿ…
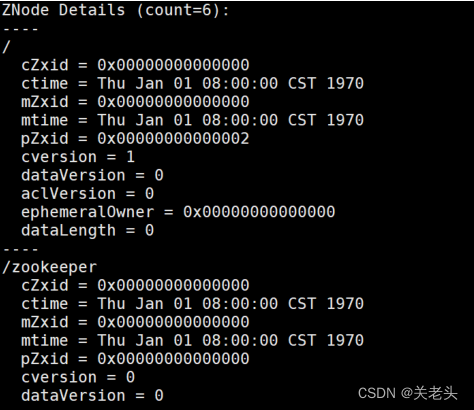
02-Zookeeper实战
上一篇:01-Zookeeper特性与节点数据类型详解
1. zookeeper安装
Step1: 配置JAVA环境,检验环境:
java -versionStep2: 下载解压 zookeeper
wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.8/apache-zookeepe…

Android Studio 的aapt2.exe在哪个目录下
一般在:C:\Users\admin\AppData\Local\Android\Sdk\build-tools\30.0.2(不一定是30.0.2,这个得看你的版本) 怎么找:
1.打开Android studio
unity lua开发体系搭建
在前面的文章里面我们已经介绍了怎么样在unity里面配置lua的开发环境,我们可以通过C#代码装载lua的脚本并执行相应的处理,这次我们一步步搭建下lua的开发体系。 1.基于c#体系所有的类都继承MonoBehaviour在这里lua环境下我们也需要创建一个类似于这个类的…

9月的一些琐碎,但值得记录的事情!
明显感觉时间过得好快,上个月还在写8月的小结,马上就是9月的了。 9月份比较忙,但是很充实,可能自己创业做事情,多少更有动力一些。 1. 要说9月份最大的事情,就是女儿开始上幼儿园了,…

功率放大器有哪些要求和标准参数
功率放大器是一种常见的电子设备,用于将输入信号增强到更高的功率级别。为了满足不同应用需求,功率放大器需要符合一些特定的要求和标准参数。 在现代电子设备中,功率放大器广泛应用于各种领域,如通信、音频放大、射频放大等。它们…
APP自动化之weditor工具
由于最近事情颇多,许久未更新文章。大家在做APP自动化测试过程中,可能使用的是Appium官方提供的inspect进行元素定位,但此工具调试不方便,于是今天给大家分享一款更好用的APP定位元素工具:weditor
weditor基于web网页…
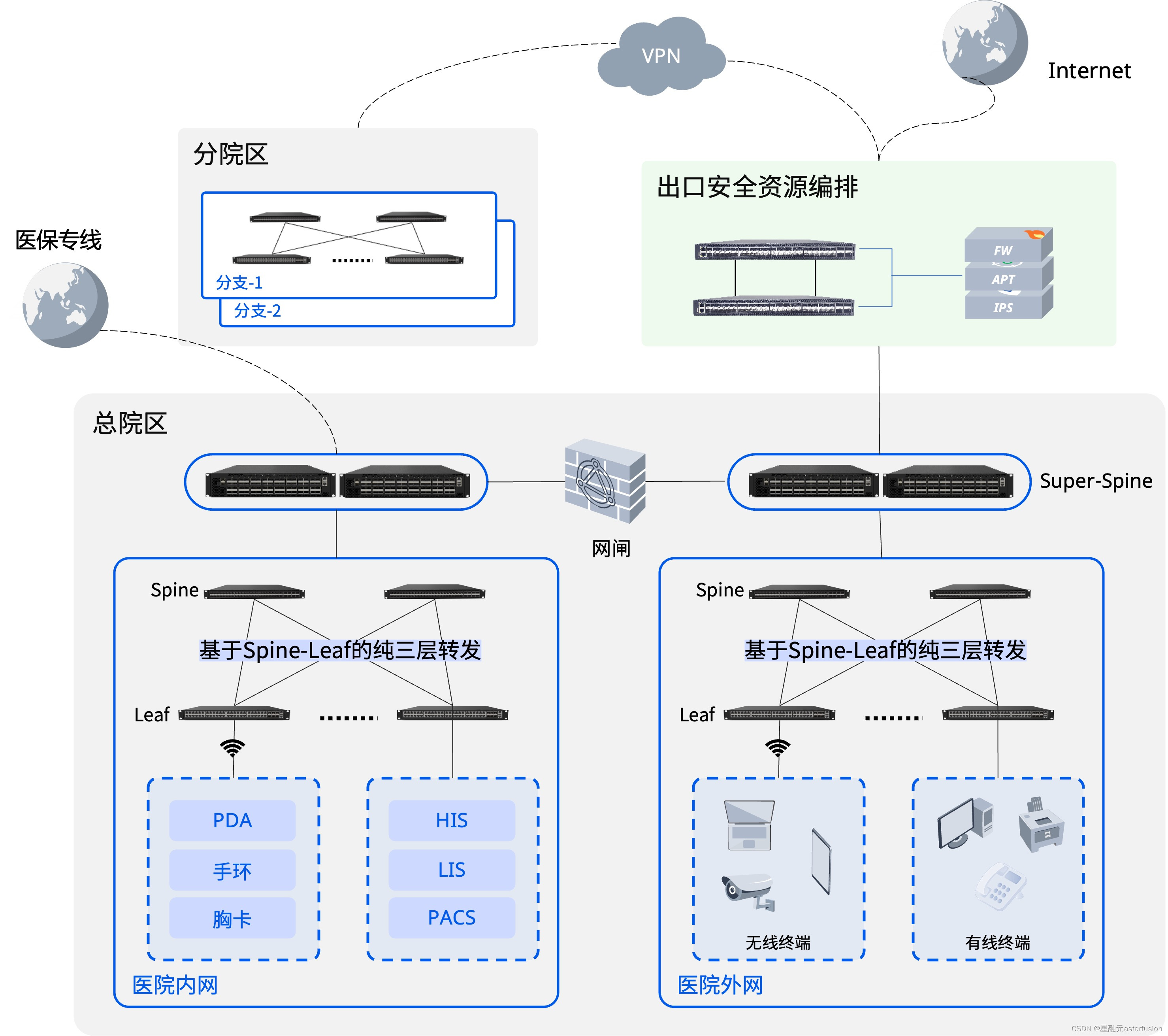
分布式网络在移动医疗场景中的应用
随着医疗信息化建设实践的深入,越来越多的医疗机构开始借助网络信息技术改善其运营及管理模式,为患者提供更高质量、更高效率、更加安全体贴的医疗服务。移动医疗便是在此背景下产生的新业务需求。
常见的移动医疗场景
住院部:移动查房、智…
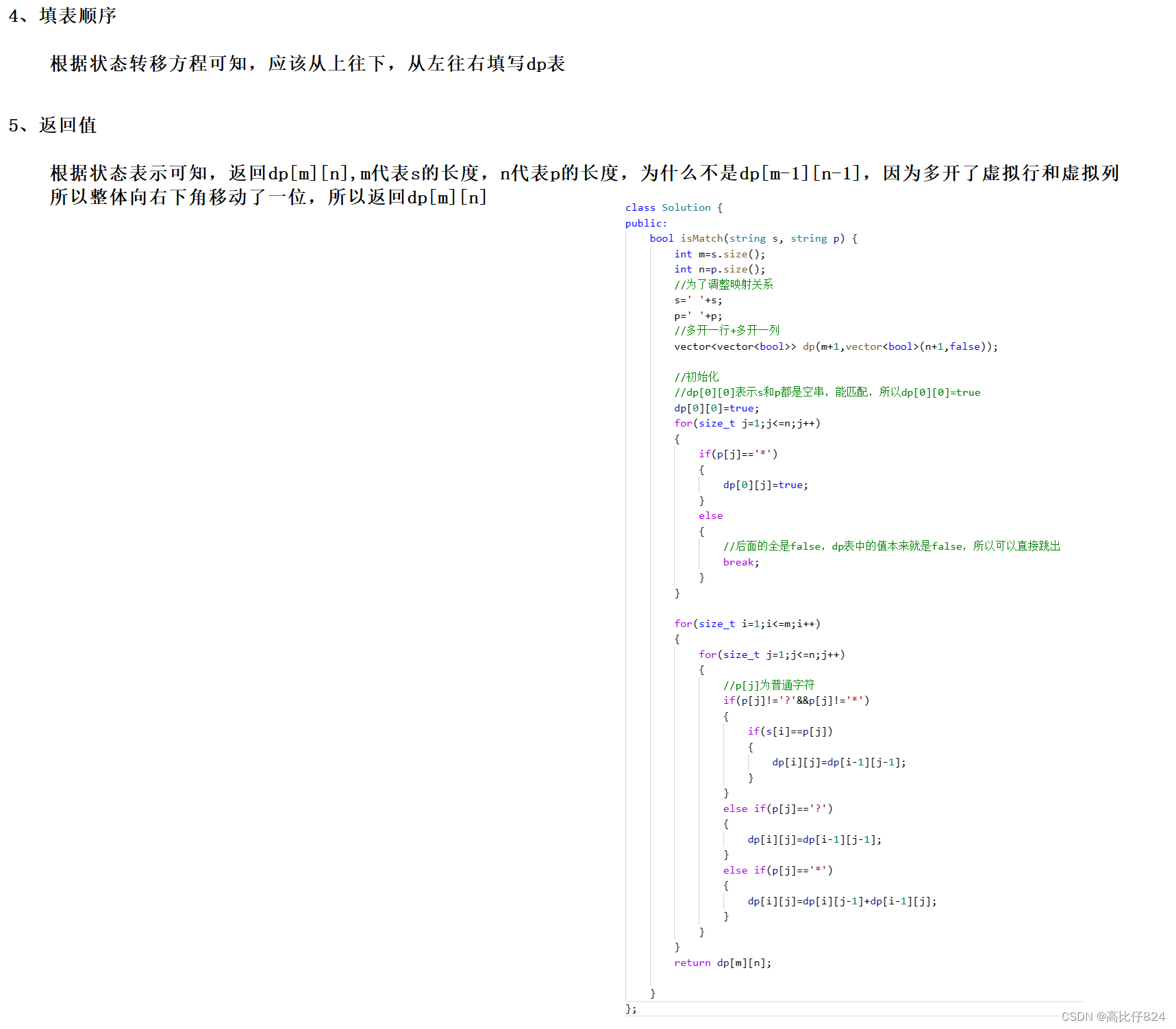
力扣 -- 44. 通配符匹配
解题步骤: 参考代码: class Solution {
public:bool isMatch(string s, string p) {int ms.size();int np.size();//为了调整映射关系s s;p p;//多开一行多开一列vector<vector<bool>> dp(m1,vector<bool>(n1,false));//初始化//dp[0]…