本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/138496.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

视频异常检测:Human Kinematics-inspired Skeleton-based Video Anomaly Detection
论文作者:Jian Xiao,Tianyuan Liu,Genlin Ji
作者单位:Nanjing Normal University;The Hong Kong Polytechnic University
论文链接:http://arxiv.org/abs/2309.15662v1
内容简介:
1)方向:视频异常检测…

第十四届蓝桥杯大赛软件赛决赛 C/C++ 大学 B 组 试题 D: 合并数列
[蓝桥杯 2023 国 B] 合并数列
【问题描述】
小明发现有很多方案可以把一个很大的正整数拆成若干正整数的和。他采取了其中两种方案,分别将他们列为两个数组 { a 1 , a 2 , ⋯ a n } \{a_1, a_2, \cdots a_n\} {a1,a2,⋯an} 和 { b 1 , b 2 , ⋯ b m } \{b…

强化学习到底是什么?它是怎么运维的
https://mp.weixin.qq.com/s/LL3HfU2iNlmSqaTX_3J7fQ 强化学习是一种行为学习模型,由算法提供数据分析反馈,引导用户逐步获取最佳结果。
来源丨Towards Data Science
作者丨Jair Ribeiro
编译丨科技行者
强化学习属于机器学习中的一个子集,它使代理能够理解在特定环境中…

【STL巨头】set、map、multiset、multimap的介绍及使用
set、map、multiset、multimap的介绍及使用 一、关联式容器二、键值对键值对概念定义 三、setset的介绍set的使用set的模板参数列表set的构造set的迭代器set的容量emptysize set的修改操作insertfind && erasecountlower_bound 和 upper_bound Multiset的用法 四、mapm…
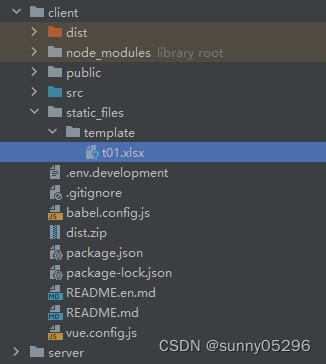
vue前端项目中添加独立的静态资源
如果想要在vue项目中放一些独立的静态资源,比如html文件或者用于下载的业务模板或其他文件等,需要在vue打包的时候指定一下静态资源的位置和打包后的目标位置。 使用的是 copy-webpack-plugin 插件,如果没有安装则需要先安装一下,…
ChatGPT必应联网功能正式上线
今日凌晨发现,ChatGPT又支持必应联网了!虽然有人使用过newbing这个阉割版的联网GPT4,但官方版本确实更加便捷好用啊!
尽管 ChatGPT 此前已经展现出了其他人工智能模型无可比拟的智能,但由于其训练数据的限制ÿ…
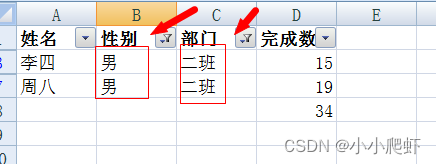
excel筛选后求和
需要对excel先筛选,后对“完成数量”进行求和。初始表格如下: 一、选中表内任意单元格,按ctrlshiftL,开启筛选 二、根据“部门”筛选,比如选择“一班” 筛选完毕后,选中上图单元格,然后按alt后&…
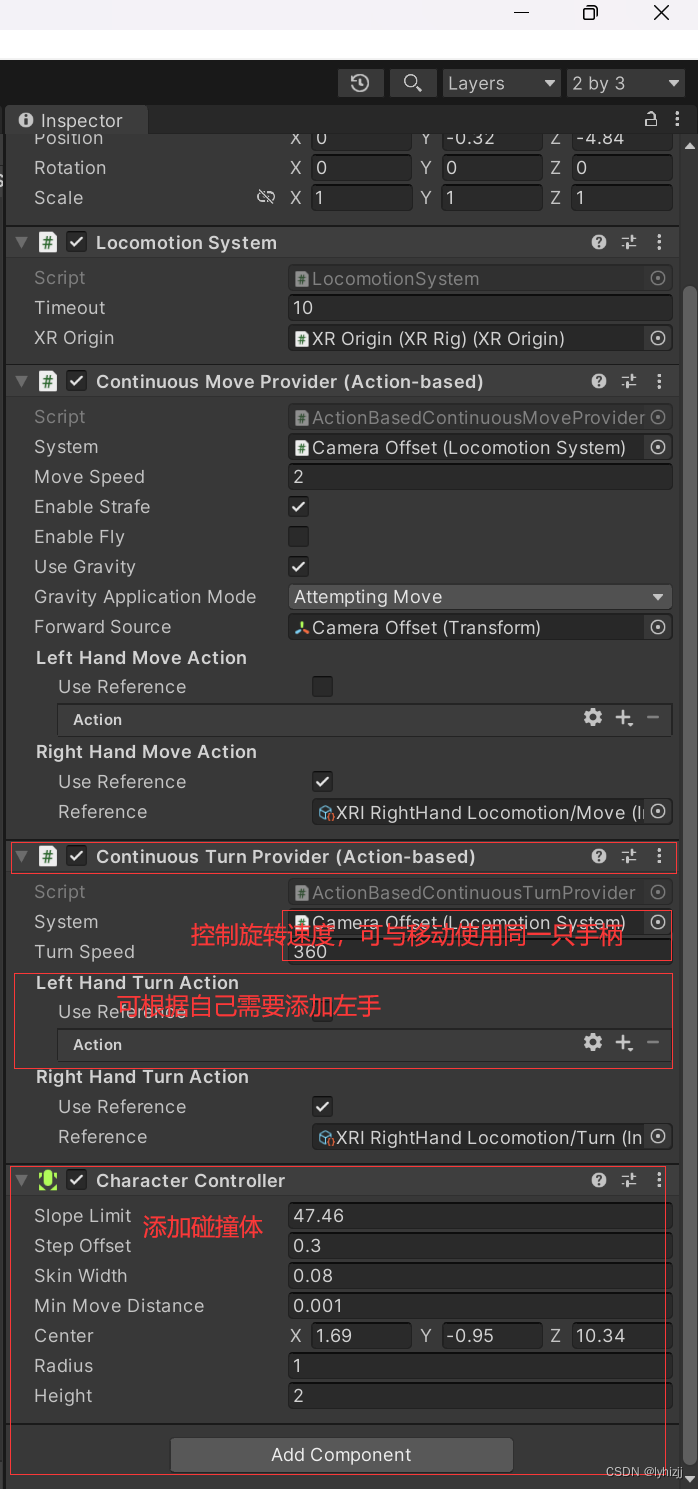
使用U3D、pico开发VR(二)——添加手柄摇杆控制移动
一、将unity 与visual studio 相关联
1.Edit->Preference->External tool 选择相应的版本 二、手柄遥控人物转向和人物移动
1.添加Locomotion System组件 选择XR Origin; 2.添加Continuous Move Provider(Action-based)组件 1>…
volatile关键字以及使用场景
在多线程环境下,如果编程不当,可能会出现程序运行结果混乱的问题。 出现这个原因主要是,JMM 中主内存和线程工作内存的数据不一致,以及多个线程执行时无序,共同导致的结果。 同时也提到引入synchronized同步锁&#x…

八、3d场景的区域光墙
在遇到区域展示的时候我们就能看到炫酷的区域选中效果,那么代码是怎么编辑的呢,今天咱们就好好说说,下面看实现效果。 思路:
首先,光墙肯定有多个,那么必须要创建一个新的js文件来作为他的原型对象。这个光…
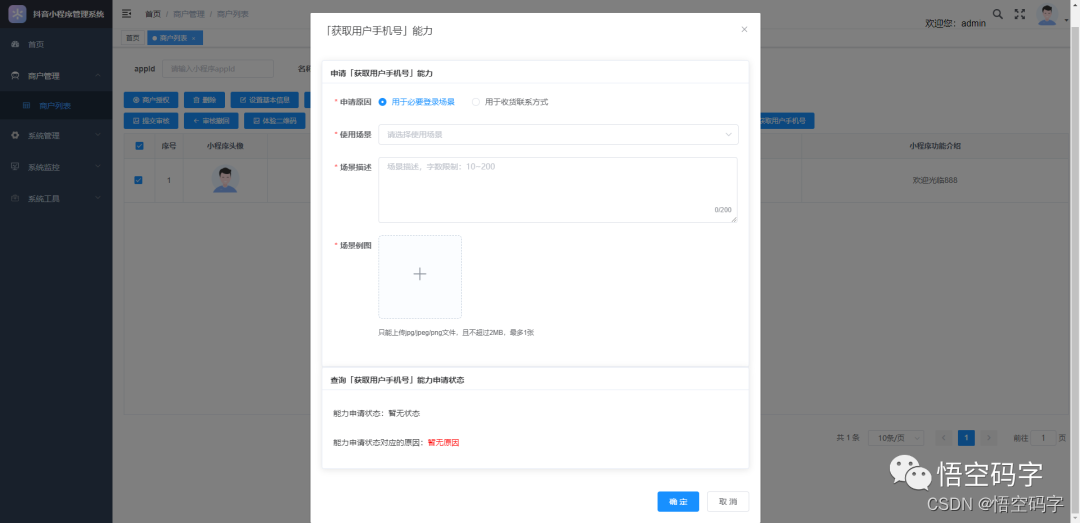
抖音开放平台第三方代小程序开发,一整套流程
大家好,我是小悟
抖音小程序第三方平台开发着力于解决抖音生态体系内的小程序管理问题,一套模板,随处部署。能尽可能地减少服务商的开发成本,服务商只用开发一套小程序代码作为模板就可以快速批量的孵化出大量的商家小程序。
第…

NLP中token总结
Token 可以被理解为文本中的最小单位。在英文中,一个 token 可以是一个单词,也可以是一个标点符号。在中文中,通常以字或词作为 token。ChatGPT 将输入文本拆分成一个个 token,使模型能够对其进行处理和理解 在自然语言处理&#…

从零开始学习 Java:简单易懂的入门指南之IO字节流(三十)
IO流之字节流 1. IO概述1.1 什么是IO1.2 IO的分类1.3 IO的流向说明图解1.4 顶级父类们 2. 字节流2.1 一切皆为字节2.2 字节输出流【OutputStream】2.3 FileOutputStream类构造方法写出字节数据数据追加续写写出换行 2.4 字节输入流【InputStream】2.5 FileInputStream类构造方法…

leetCode 122.买卖股票的最佳时机 II 动态规划 + 状态转移 + 状态压缩
122. 买卖股票的最佳时机 II - 力扣(LeetCode)
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买&…
Halcon 从基础到精通-01- 基本概念
1 HALCON Architecture 【图一】
HALCON的架构如上,其主要的部分,就是图像处理库。 2 HALCON的基本架构
2.1 Operators
HALCON库功能的使用都是通过【operators】操作符来实现的。绝大多数的操作符由多种方法构成,具体可以参考给出的下面…
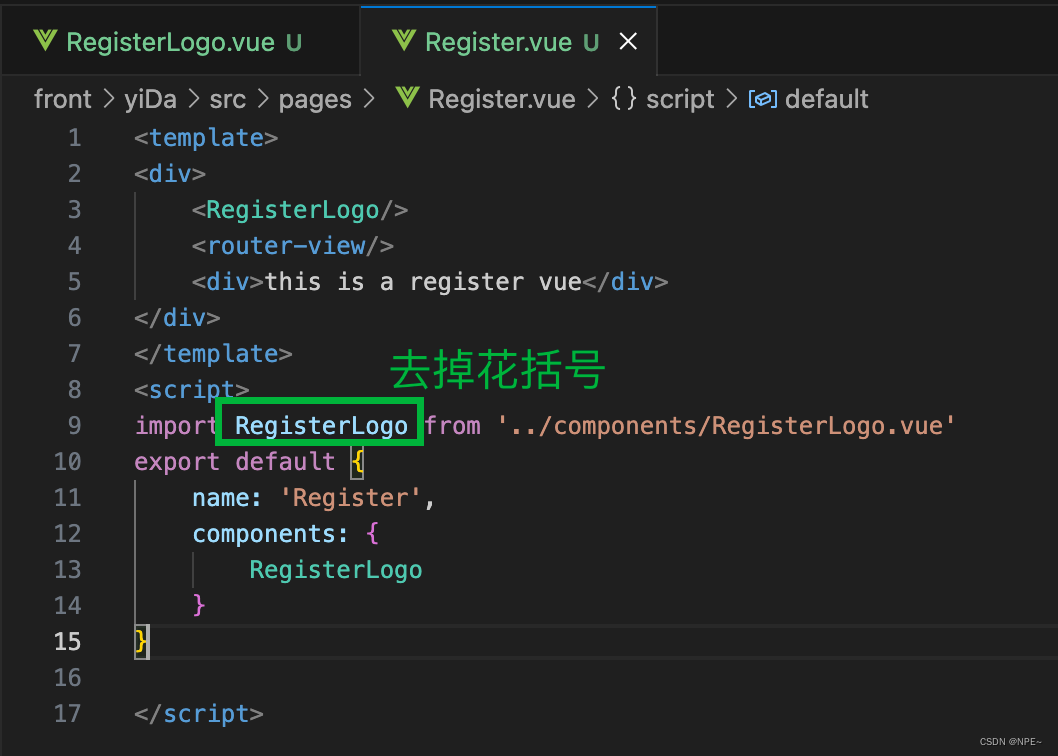
Bug:elementUI样式不起作用、Vue引入组件报错not found等(Vue+ElementUI问题汇总)
前端问题合集:VueElementUI
1. Vue引用Element-UI时,组件无效果解决方案 前提: 已经安装好elementUI依赖 //安装依赖
npm install element-ui
//main.js中导入依赖并在全局中使用
import ElementUI from element-ui
Vue.use(ElementUI)如果此…

windows下python开发环境的搭建 python入门系列 【环境搭建篇】
在正式学习Python之前要先搭建Python开发环境。由于Python是跨平台的,所以可以在多个操作系统上进行编程
一、python的下载安装与配置
1、Python解释器
1. 要进行Python开发,首先需要Python解释器,这里说的安装Python就是安装Python解释器…
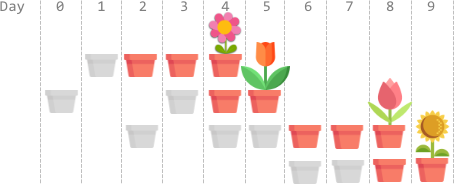
LeetCode每日一题:2136. 全部开花的最早一天(2023.9.30 C++)
目录
2136. 全部开花的最早一天
题目描述:
实现代码与解析:
贪心
原理思路: 2136. 全部开花的最早一天
题目描述: 你有 n 枚花的种子。每枚种子必须先种下,才能开始生长、开花。播种需要时间,种子的生…
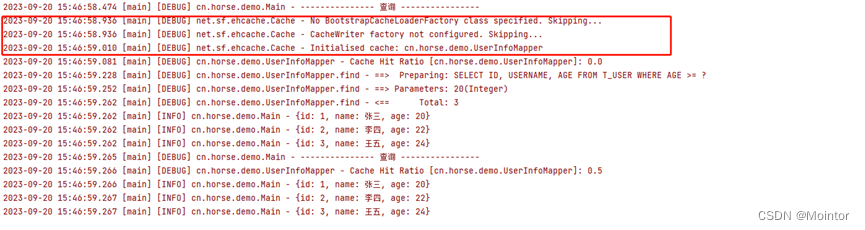
Mybatis 二级缓存(使用Ehcache作为二级缓存)
上一篇我们介绍了mybatis中二级缓存的使用,本篇我们在此基础上介绍Mybatis中如何使用Ehcache作为二级缓存。
如果您对mybatis中二级缓存的使用不太了解,建议您先进行了解后再阅读本篇,可以参考:
Mybatis 二级缓存https://blog.c…
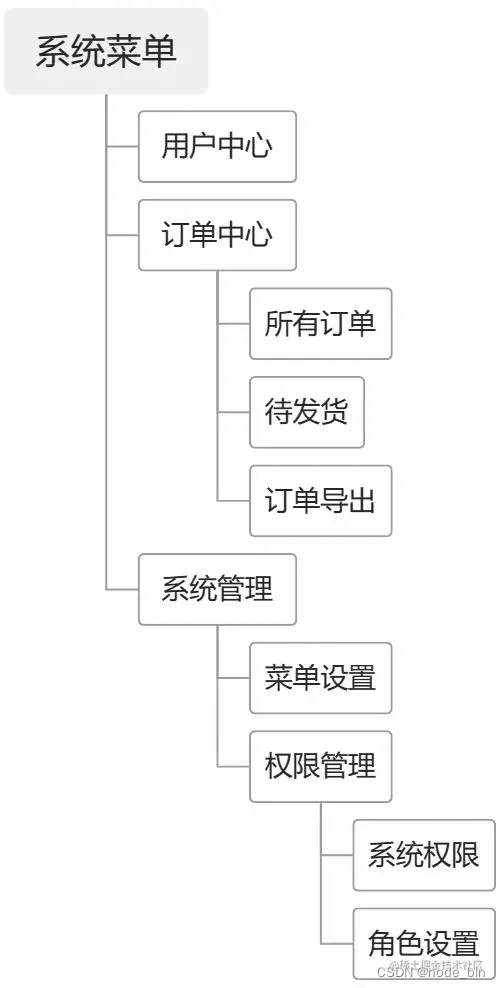
JS前端树形Tree数据结构使用
前端开发中会经常用到树形结构数据,如多级菜单、商品的多级分类等。数据库的设计和存储都是扁平结构,就会用到各种Tree树结构的转换操作,本文就尝试全面总结一下。
如下示例数据,关键字段id为唯一标识,pid为父级id&am…