本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/343295.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
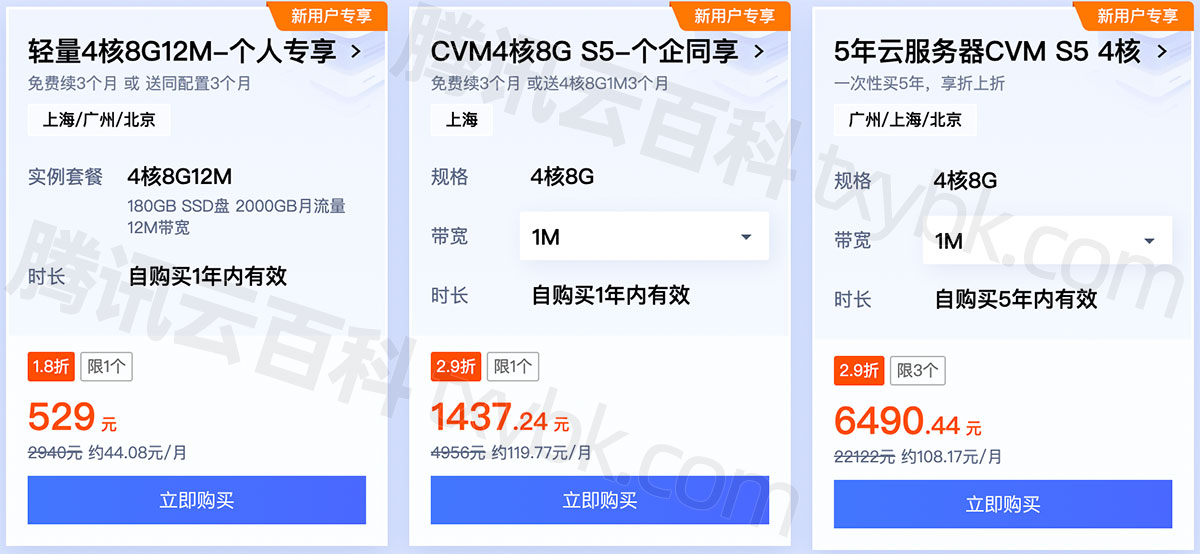
腾讯云4核8G服务器可以用来干嘛?怎么收费?
腾讯云4核8G服务器适合做什么?搭建网站博客、企业官网、小程序、小游戏后端服务器、电商应用、云盘和图床等均可以,腾讯云4核8G服务器可以选择轻量应用服务器4核8G12M或云服务器CVM,轻量服务器和标准型CVM服务器性能是差不多的,轻…

NAT——网络地址转换、NAPT
网络地址转换 NAT (Network Address Translation)
1994 年提出。
需要在专用网连接到互联网的路由器上安装 NAT 软件。
装有 NAT 软件的路由器叫做 NAT路由器,它至少有一个有效的外部全球 IP 地址。
所有使用本地地址的主机在和外界通信时,都要在 NA…
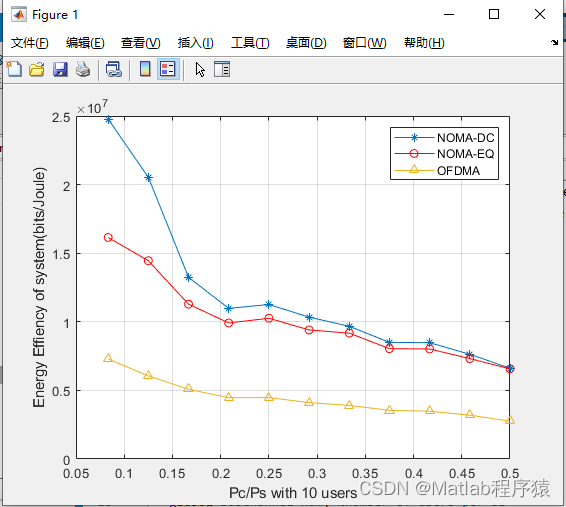
【MATLAB源码-第137期】基于matlab的NOMA系统和OFDMA系统对比仿真。
操作环境:
MATLAB 2022a
1、算法描述
NOMA(非正交多址)和OFDMA(正交频分多址)是两种流行的无线通信技术,广泛应用于现代移动通信系统中,如4G、5G和未来的6G网络。它们的设计目标是提高频谱效…
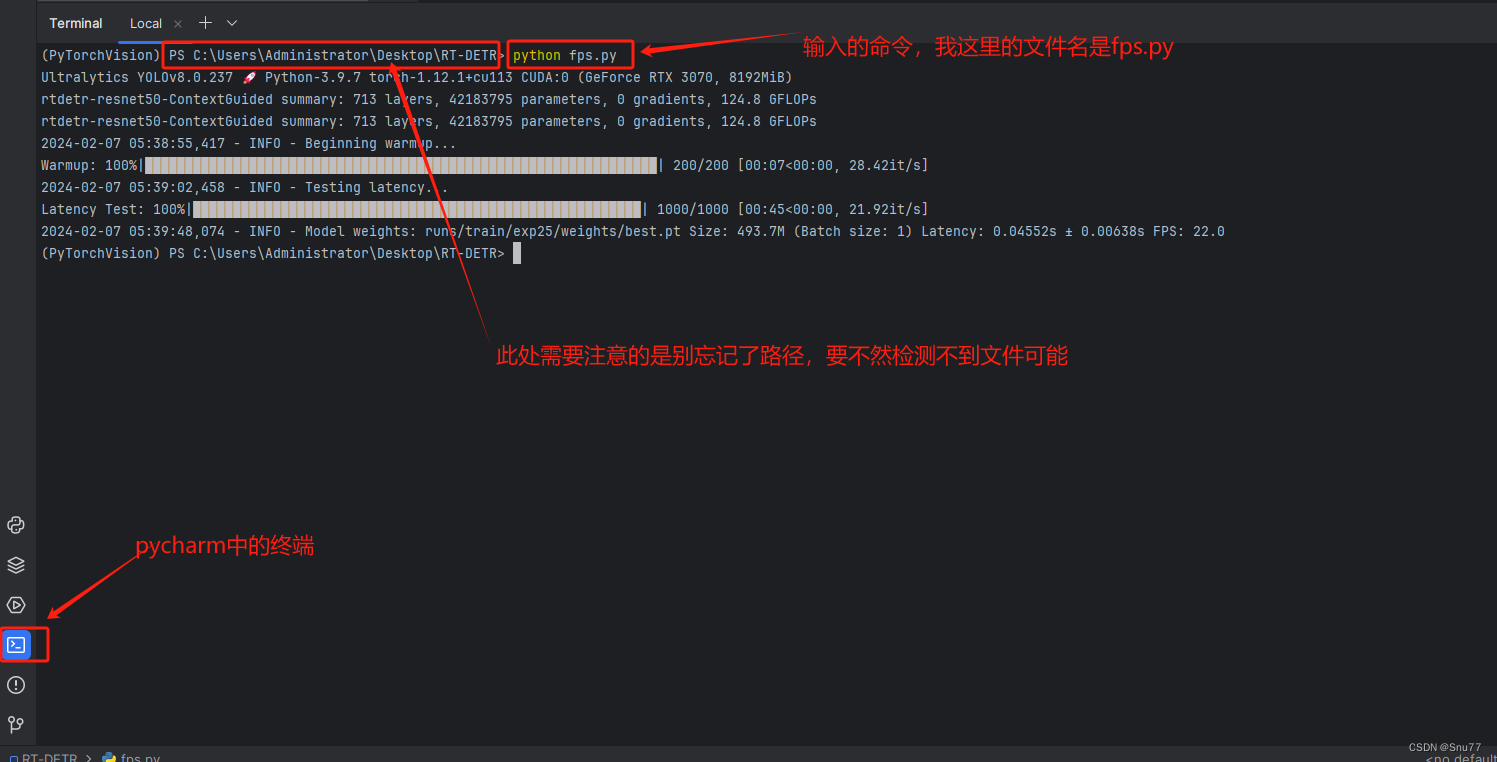
【RT-DETR有效改进】计算训练好权重文件对应的FPS、推理每张图片的平均时间(科研必备)
👑欢迎大家订阅本专栏,一起学习RT-DETR👑 一、本文介绍
本文给大家带来的改进机制是利用我们训练好的权重文件计算FPS,同时打印每张图片所利用的平均时间,模型大小(以MB为单位),同时支持batch_size功能的选择,对于轻量化模型的读者来说,本文的内容对你一定有…
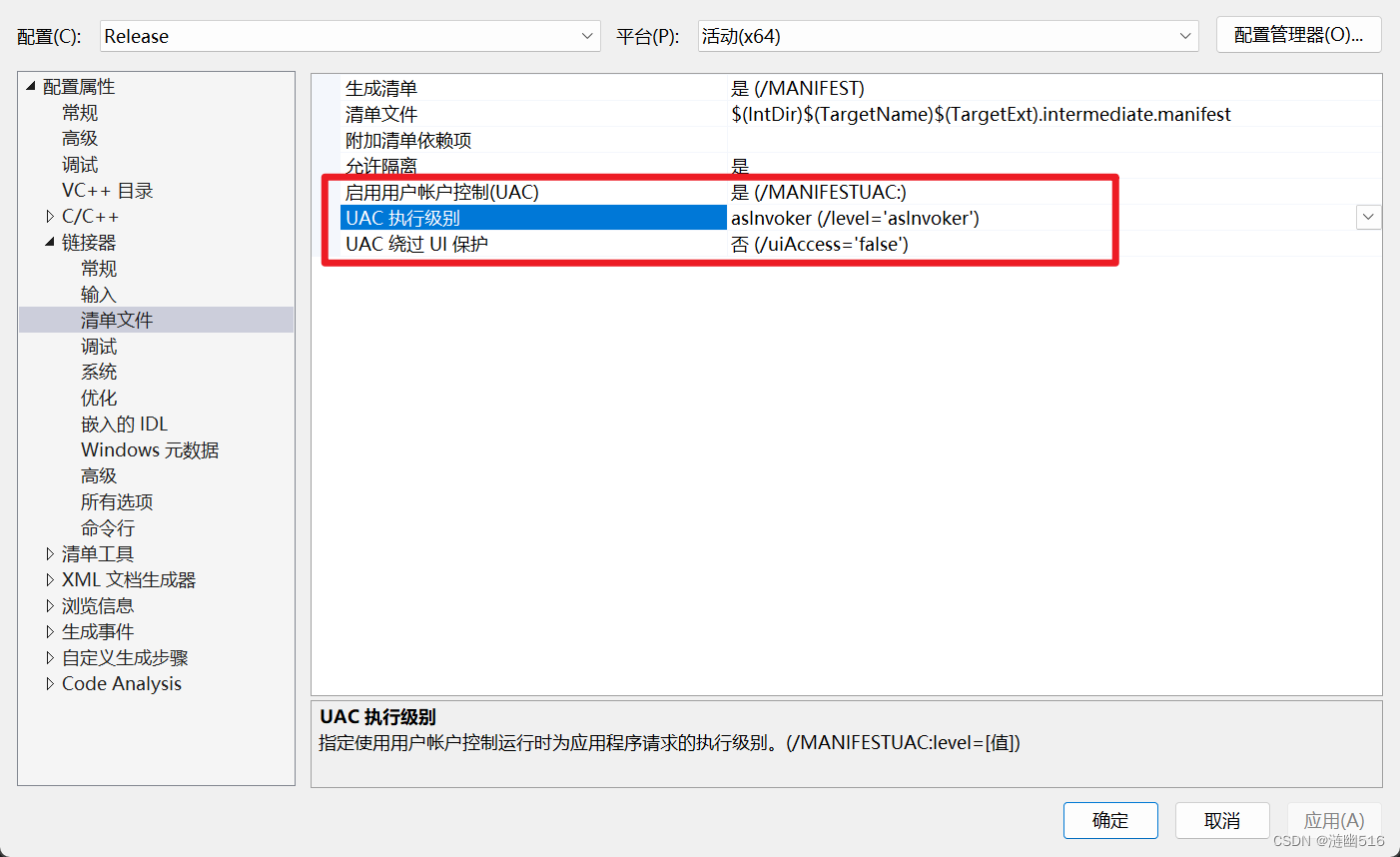
PE 特征码定位修改程序清单 uiAccess
requestedExecutionLevel level"asInvoker" uiAccess"false" 可以修改这一行来启用禁用原程序的盾牌图标,似乎作用不大。以前没事写的一个小玩意,记录一下。
等同于这里的设置: 截图 代码如下:
#include …
跨境电商新风潮:充分发挥海外云手机的威力
在互联网行业迅速发展的大环境下,跨境电商、海外社交媒体营销以及游戏产业等重要领域都越来越需要借助海外云手机的协助。 特别是在蓬勃发展的跨境电商领域,像亚马逊、速卖通、eBay等平台,结合社交电商营销和短视频内容成为最有效的流量来源。…
Stable Diffusion 模型下载:majicMIX reverie 麦橘梦幻
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十
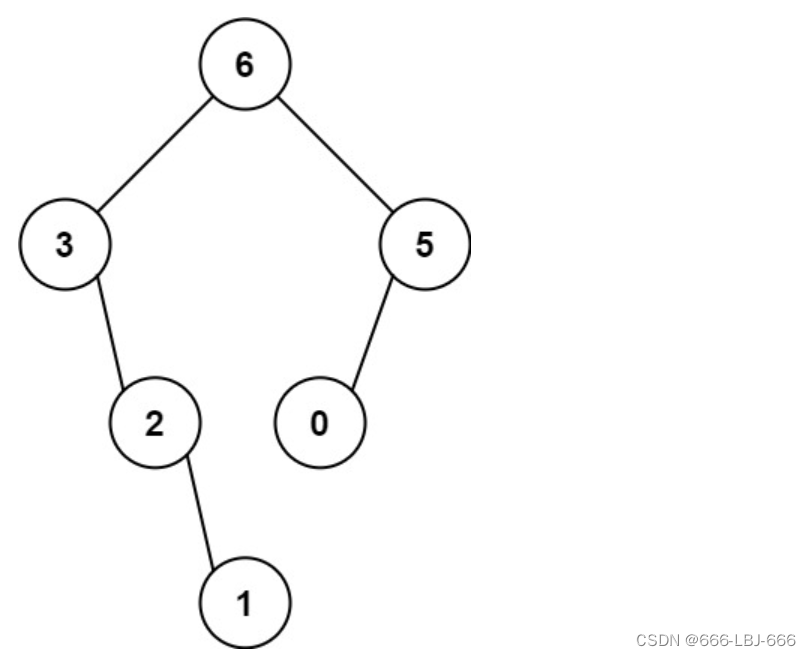
每日一练:LeeCode-654、最大二叉树【二叉树+DFS+分治】
本文是力扣LeeCode-654、最大二叉树【二叉树DFS分治】 学习与理解过程,本文仅做学习之用,对本题感兴趣的小伙伴可以出门左拐LeeCode。
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
创建一个根节点,其…
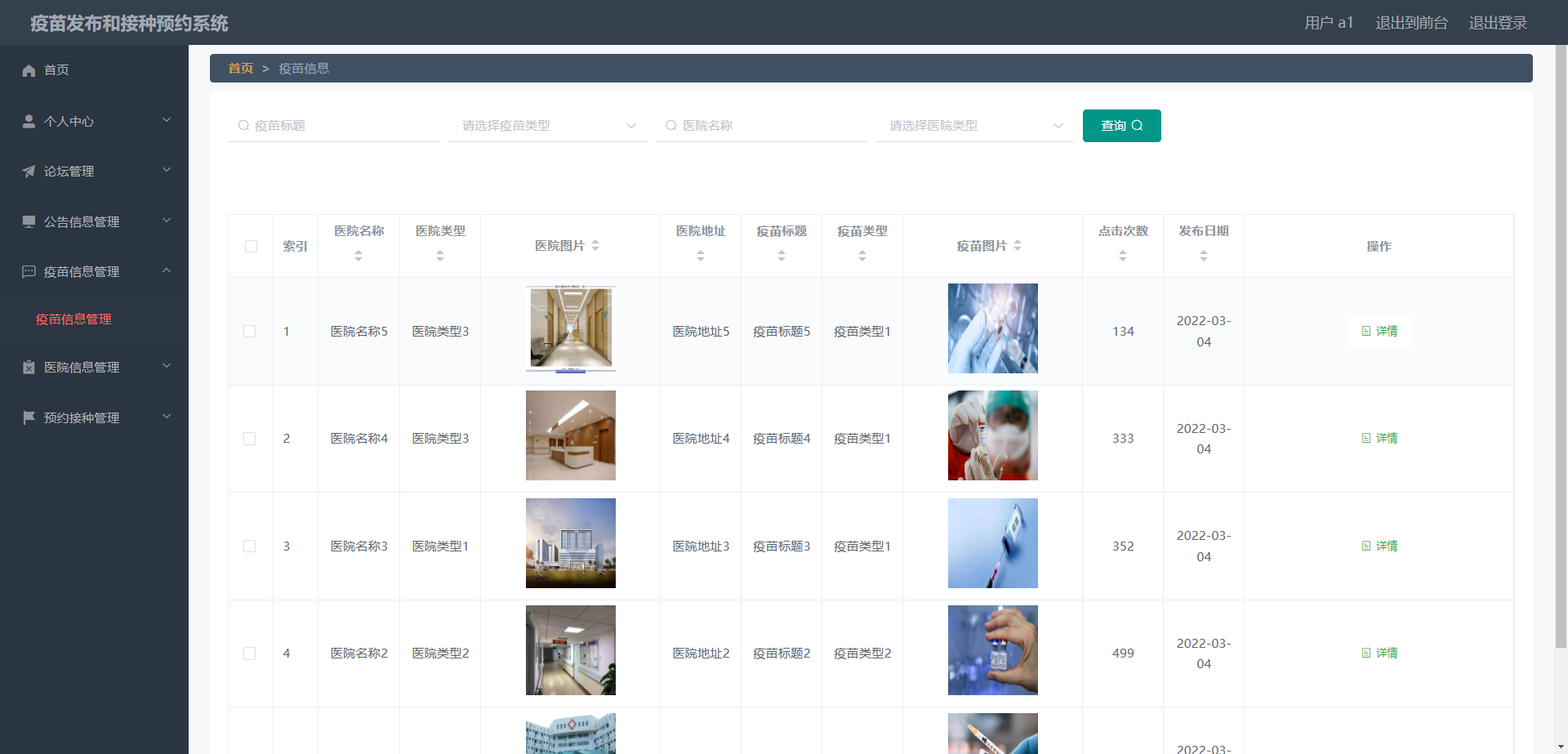
精品springboot疫苗发布和接种预约系统
《[含文档PPT源码等]精品基于springboot疫苗发布和接种预约系统[包运行成功]》该项目含有源码、文档、PPT、配套开发软件、软件安装教程、项目发布教程、包运行成功!
软件开发环境及开发工具:
Java——涉及技术:
前端使用技术:…

【数据分享】1929-2023年全球站点的逐日降水量数据(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、湿度等指标,说到常用的降水数据,最详细的降水数据是具体到气象监测站点的降水数据!
有关气象指标的监测站点数据,之前我们分享过1929-2023年全…

分享76个文字特效,总有一款适合您
分享76个文字特效,总有一款适合您
76个文字特效下载链接:https://pan.baidu.com/s/1rIiUdCMQScoRVKhFhXQYpw?pwd8888
提取码:8888
Python采集代码下载链接:采集代码.zip - 蓝奏云
学习知识费力气,收集整理更不…

小白水平理解面试经典题目LeetCode 102 Binary Tree Level Order Traversal【二叉树】
102. 二叉树层次顺序遍历
小白渣翻译
给定二叉树的 root ,返回其节点值的层序遍历。 (即从左到右,逐级)。
例子 小白教室做题
在大学某个自习的下午,小白坐在教室看到这道题。想想自己曾经和白月光做题,…
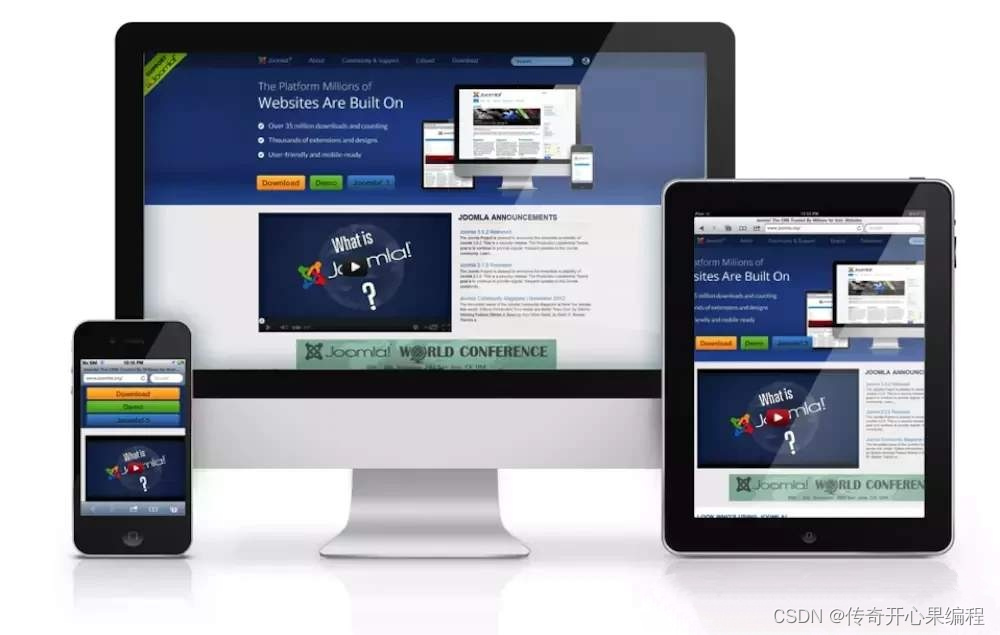
第六篇【传奇开心果系列】Vant of Vue 开发移动应用示例:深度解析响应式布局支持
传奇开心果系列 系列博文目录Vant开发移动应用示例系列 博文目录前言一、Vant响应式布局介绍二、媒体查询实现响应式布局示例代码三、短点设置实现响应式布局示例代码四、响应式工具类实现响应式布局示例代码五、栅格系统实现响应式布局示例代码六、响应式组件实现响应式布局示…
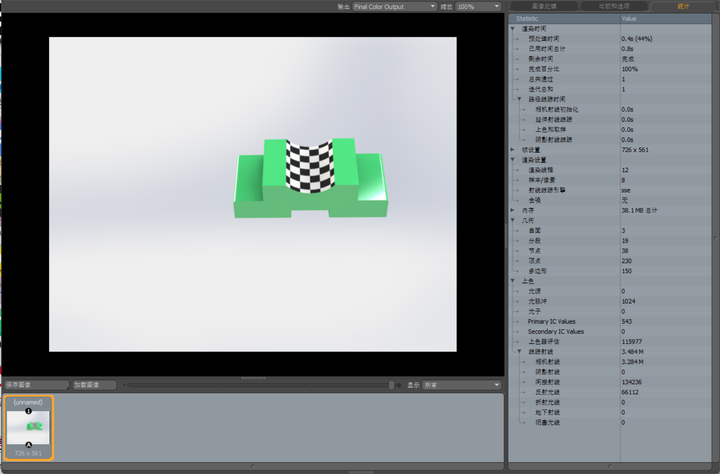
SolidWorks学习笔记——入门知识2
目录 建出第一个模型
1、建立草图
2、选取中心线
3、草图绘制
4、拉伸
特征的显示与隐藏
改变特征名称
5、外观
6、渲染 建出第一个模型
1、建立草图 图1 建立草图
按需要选择基准面。
2、选取中心线 图2 选取中心线
3、草图绘制
以对称图形举例,先画出…

《傲剑狂刀》中的人物性格——龙吟风
在《傲剑狂刀》这款经典武侠题材的格斗游戏中,龙吟风作为一位具有传奇色彩的角色,其性格特征复杂且引人入胜。以下是对龙吟风这一角色的性格特点进行深度剖析:
一、孤高独立的剑客气质 龙吟风的名字本身就流露出一种独特的江湖气息,"吟风"象征着他的飘逸与淡泊名…

鸿蒙开发第3篇__大数据量的列表加载性能优化
列表 是最常用到的组件
一 ForEach
渲染控制语法————Foreach Foreach的作用
遍历数组项,并创建相同的布局组件块在组件加载时, 将数组内容数据全部创建对应的组件内容, 渲染到页面上
const swiperImage: Resource[] {$r("app.me…
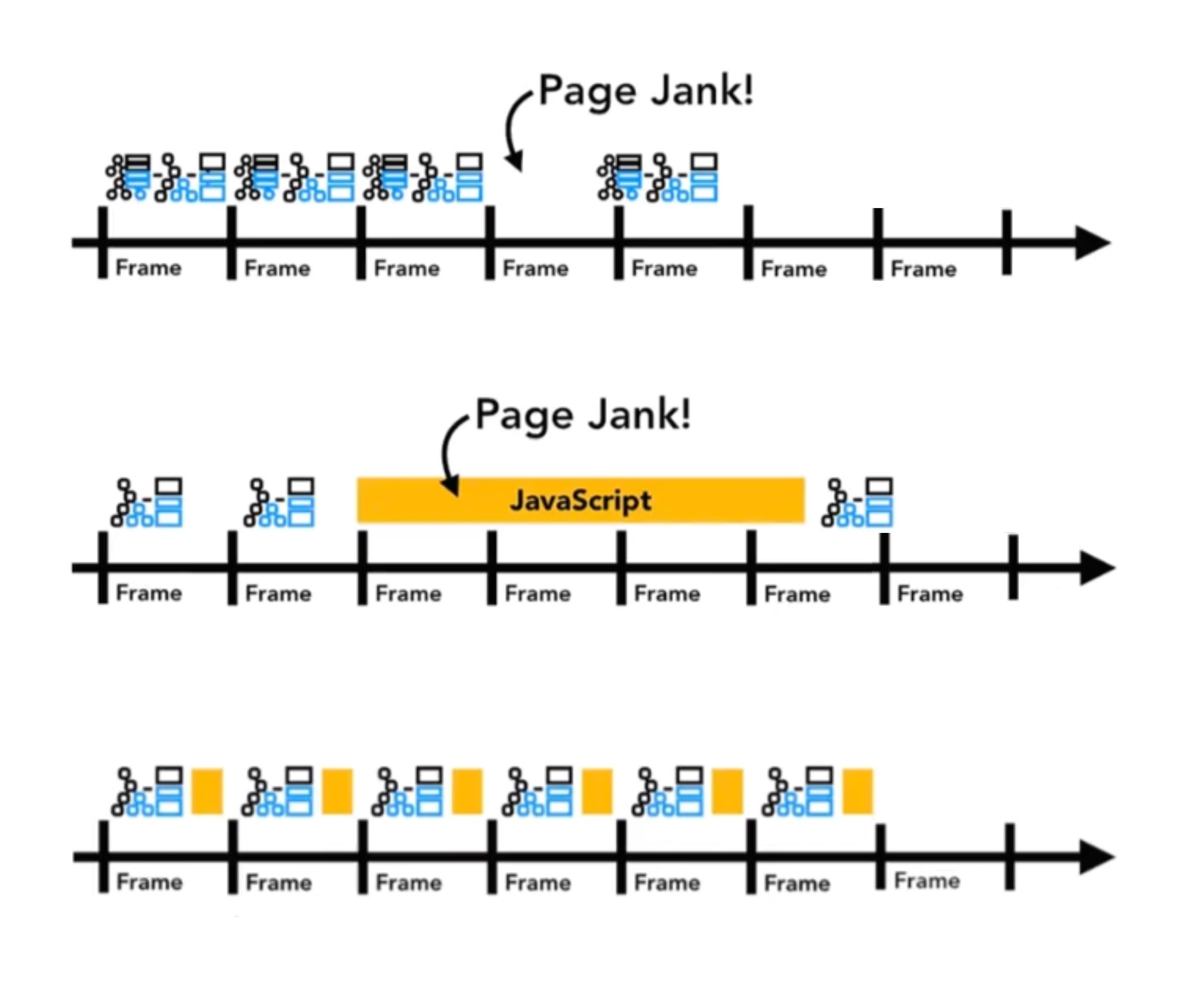
React18原理: 再聊Fiber架构下的时间分片
时间分片
react的任务可以被打断,其实就是基于时间分片的人眼最高能识别的帧数不超过30帧,电影的帧数差不多是在24浏览器的帧率一般来说是60帧,也就是每秒60个画面, 平均一个画面大概是16.5毫秒左右浏览器正常的工作流程是运算渲染ÿ…

专业140+总分410+华南理工大学811信号与系统考研经验华工电子信息与通信,真题,大纲,参考书。
23考研已经落幕,我也成功的上岸华工,回首这一年多的历程,也是有一些经验想和大家分享一下。
首先说一下个人情况,本科211,初试成绩400分。专业课140。
整体时间安排
对于考研,很重要的一环就是时间安排&…

Mac上几款好用的MacBook视频播放器
使用Mac电脑时,视频播放器可以说是我们使用频率最高的软件之一了,不管是工作时看视频资料还是在家里看下载好的电影,都需要用到视频播放器,本文中我们就来推荐几款好用的Macbook视频播放器,总有一款适合你!…

Xcode配置GLFW GLAD (MAC)
这里的GLFW用的是静态链接 博主反复修改,实在是没能找到为什么用动态会出现线程报错
下载GLAD:版本我一般是选倒数第二新,profile记得选core 点击GENRATE 点glad.zip获得下载 下载GLFW
点击download 最后,将两个文件都放到项目里面去 打开…