本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/438529.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
聊聊Redis分布式锁的八大坑
前言
在分布式系统中,由于redis分布式锁相对于更简单和高效,成为了分布式锁的首先,被我们用到了很多实际业务场景当中。
但不是说用了redis分布式锁,就可以高枕无忧了,如果没有用好或者用对,也会引来一些…

JavaEE-HTTPHTTPS
目录 HTTP协议
一、概念
二、http协议格式
http请求报文
http响应报文
URL格式
三、认识方法
四、认识报头
HTTP响应中的信息
HTTPS协议
对称加密
非对称加密
中间人攻击
解决中间人攻击 HTTP协议
一、概念 HTTP (全称为 "超⽂本传输协议") 是⼀种应⽤…


最新实践!如何基于 DB-GPT 搭建财报分析助手?
DB-GPT
财报分析助手
精准解析数据
实现智慧决策
背景
最近,利用大模型进行财务报表分析正逐渐成为垂直领域的一个热门应用。大模型能够比人类更准确地理解复杂的财务规则,并在基于专业知识的基础上输出合理的分析结果。然而,财务报表信…

web3.0区块链元宇宙是什么
Web3.0
什么是 Web3.0
Web3.0是指基于区块链的去中心化在线生态系统,代表了互联网的下一个阶段。它是由以太坊联合创始人Gavin Wood在2014年创造的概念。Web3.0的发展是随着用户权利的增加和在互联网中角色的重要性不断进化的。 从互联网的发展历程来看࿰…

opencv之形态学
文章目录 1. 什么是形态学2. 形态学操作2.1 腐蚀2.2 膨胀2.3 通用形态学函数2.4 开运算2.5 闭运算2.6 形态学梯度运算2.7 礼帽运算2.8 黑帽运算 1. 什么是形态学 在图像处理领域,形态学是一种基于形状的图像分析技术,用于提取和处理图像的形态特征。这包…
【科研绘图】【风筝图】:附Origin详细画图流程
目录
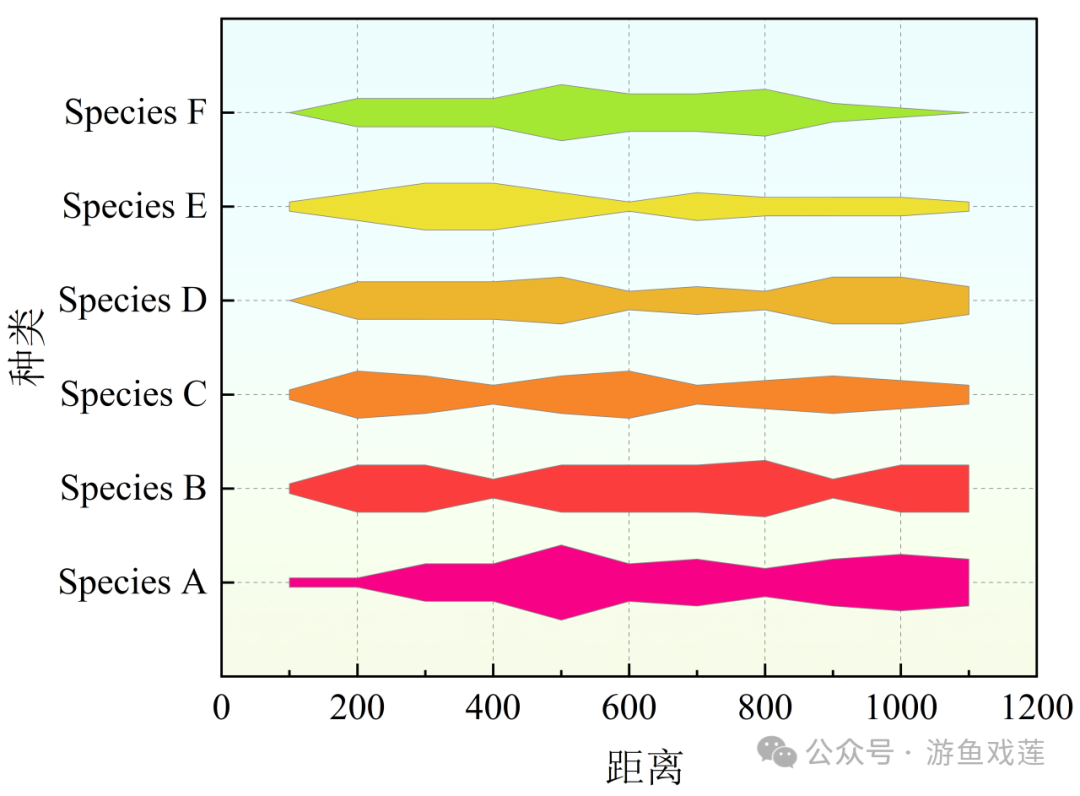
No.1 理解风筝图
1 什么是风筝图
2 解读风筝图
No.2 画图流程
1 导入数据,绘制图形
2 设置绘图细节
3 设置坐标轴
4 效果图 No.1 理解风筝图
1 什么是风筝图 风筝图,也称为点图或散点图的一种变体,在生态学和环境科学中&#x…


25考研人数预计下降?这一届考研有哪些新趋势?
2025年考研时间线:
2024年9月:公共课及各院校考试大纲公布;
2024年9月下旬:预报名;
2024年10月:正式报名;
2024年11月:线上/线下确认;
2024年12月中下旬:…

上传本地项目到git上面
文章目录 1.服务器创建一个空项目1.1.创建项目1.2.界面可能不一样 2.上传新项目到git上面2.1.将远程项目拉取到本地进行上传1. 将项目克隆到本地:(为了建立本地仓库和远程仓库关系方便推送)2. 建立本地仓库和远程仓库关系并推送(如…

百度地图SDK Android版开发 10 InfoWindow
百度地图SDK Android版开发 10 InfoWindow 前言InfoWindow 相关类和接口BaiduMap类InfoWindow 类构造方法gettersetterOnInfoWindowClickListener 接口 InfoWindowAdapter 相关类和方法BaiduMap类InfoWindowAdapter 接口Marker 类 示例界面布局MapInfoWindow类常量成员变量初始…


数据结构——单链表查询、逆序、排序
1、思维导图 2、查、改、删算法
//快慢排序法找中间值
int mid_link(Link_t *plink)
{Link_Node_t *pfast plink->phead;Link_Node_t *pslow pfast;int m 0;while(pfast ! NULL){pfast pfast->pnext;m;if(m % 2 0){pslow pslow->pnext;}}printf("%d\n&quo…

大数据-117 - Flink DataStream Sink 案例:写出到MySQL、写出到Kafka
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…

CDA数据分析一级考试备考攻略
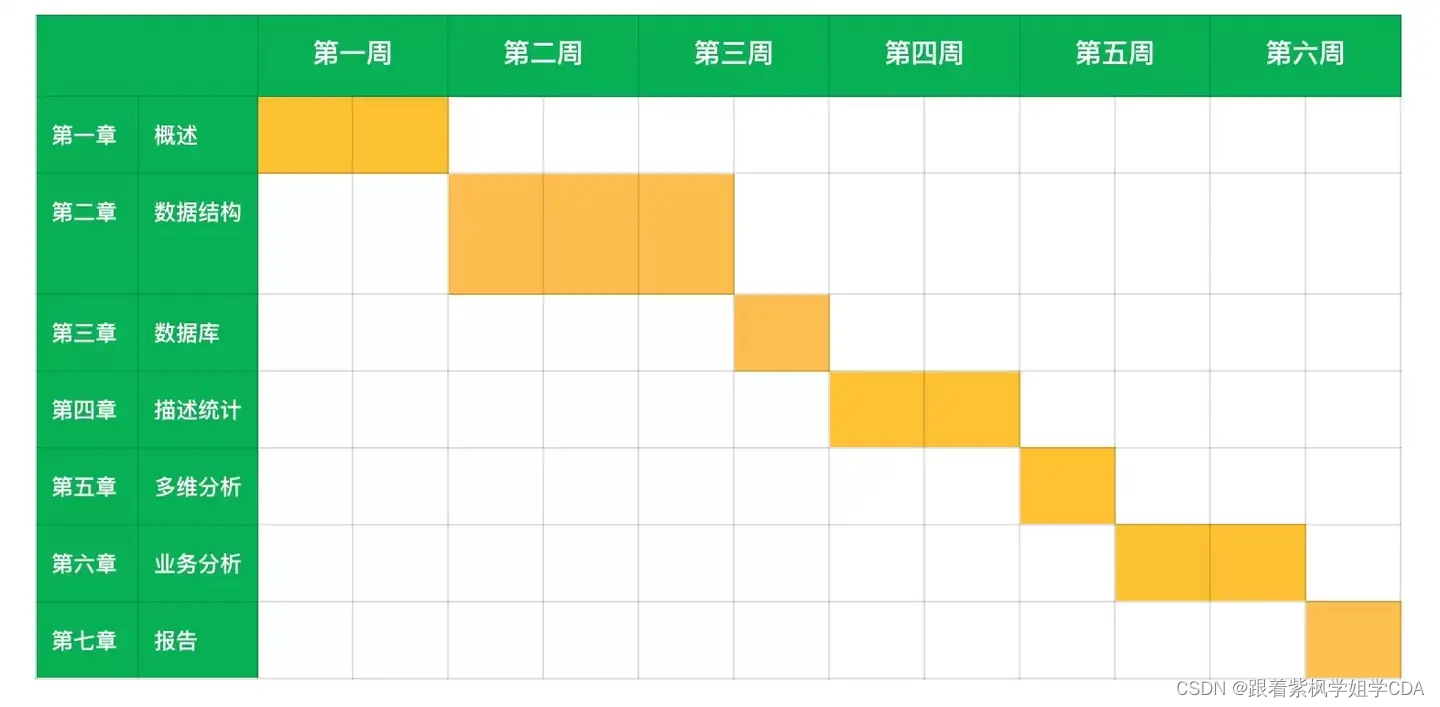
一、了解考试内容和结构
CDA一级考试主要涉及的内容包括:数据分析概述与职业操守、数据结构、数据库基础与数据模型、数据可视化分析与报表制作、Power BI应用、业务数据分析与报告编写等。
CDA Level Ⅰ 认证考试大纲:https://www.cdaglobal.com/certification.h…

开源通用验证码识别OCR —— DdddOcr 源码赏析(二)
文章目录 前言DdddOcr分类识别调用识别功能classification 函数源码classification 函数源码解读1. 分类功能不支持目标检测2. 转换为Image对象3. 根据模型配置调整图片尺寸和色彩模式4. 图像数据转换为浮点数据并归一化5. 图像数据预处理6. 运行模型,返回预测结果 …

海洋运输船5G智能工厂物联数字孪生平台,推进制造业数字化转型
海洋运输船5G智能工厂物联数字孪生平台,推进制造业数字化转型。在当今全球制造业的浪潮中,数字化转型已成为不可逆转的趋势,它不仅重塑了生产流程,更深刻影响着企业的竞争力与可持续发展能力。其中,海洋运输船5G智能工…


爬虫 可视化 管理:scrapyd、Gerapy、Scrapydweb、spider-admin-pro、crawllab、feaplat、XXL-JOB
1、scrapyd 大多数现有的平台都依赖于 Scrapyd,这将选择限制在 python 和 scrapy 之间。当然 scrapy 是一个很棒的网络抓取框架,但是它不能做所有的事情。
对于重度 scrapy 爬虫依赖的、又不想折腾的开发者,可以考虑 Scrapydweb;…