本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/439749.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

vim 安装与配置教程(详细教程)
vim就是一个功能非常强大的文本编辑器,可以自己DIY的那种 ,不但可以写代码 ,还可编译 ,可以让你手不离键盘的完成鼠标的所有操作。 如果想要了解vim的的发展历史和详细解说,可以自行上网搜索,我主要是记录一…

Clion不识别C代码或者无法跳转C语言项目怎么办?
如果是中文会显示:
此时只需要右击项目,或者你的源代码目录,将这个项目或者源码目录标记为项目源和头文件即可。
英文如下:

大数据-124 - Flink State 01篇 状态原理和原理剖析:状态类型 执行分析
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…

了解一下HTTP 与 HTTPS 的区别
介绍: HTTP是超文本传输协议。规定了客户端(通常是浏览器)和服务器之间如何传输超文本,也就是包含链接的文本。通常使用TCP【1】/IP协议来传输数据,默认端口为80。 HTTPS是超文本传输安全协议,具有CA证书。…

VR虚拟展厅的应用场景有哪些?
虚拟展厅作为一种利用虚拟现实技术构建的三维展示空间,其应用场景广泛且多样。视创云展为企业虚拟展厅搭建提供技术支持。以下是一些主要的应用场景: 1. 博物馆和艺术展览
文物保护与展示:
在博物馆中,为了保护珍贵的文物和艺术…

2025年25届计算机毕业设计:如何实现高校实验室Java SpringBoot教学管理系统
✍✍计算机毕业编程指导师** ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java…
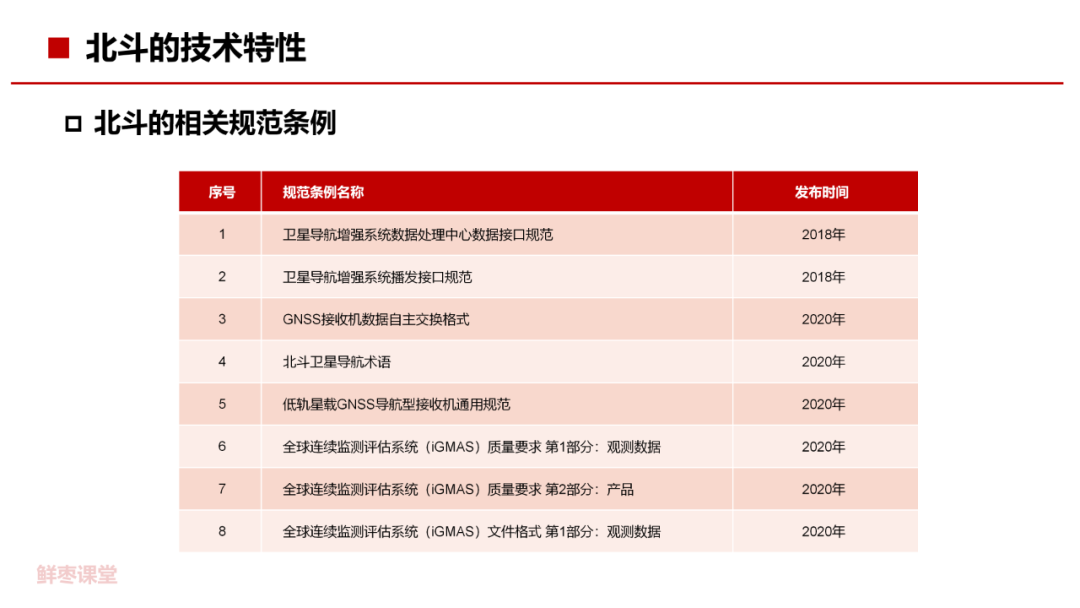
【一文读懂】北斗卫星导航系统介绍
前言
本文来自鲜枣课堂。
本文是关于北斗卫星导航系统的详细介绍,主要阐述了北斗系统的组成、功能、发展历程以及在全球范围内的应用和影响。以下是文件的核心内容提炼:
系统概述: 二级要点关键短语:全球卫星导航系统 北斗卫星…

【鸿蒙HarmonyOS NEXT】页面之间相互传递参数
【鸿蒙HarmonyOS NEXT】页面之间相互传递参数 一、环境说明二、页面之间相互传参 一、环境说明 DevEco Studio 版本: API版本:以12为主
二、页面之间相互传参
说明: 页面间的导航可以通过页面路由router模块来实现。页面路由模块根据页…

idea插件开发的第二天-写一个时间查看器
介绍
Demo说明
本文基于maven项目开发,idea版本为2022.3以上,jdk为1.8本文在Tools插件之上进行开发
Tools插件说明
Tools插件是一个Idea插件,此插件提供统一Spi规范,极大的降低了idea插件的开发难度,并提供开发者模块,可以极大的为开发者开发此插件提供便利Tools插件安装需…

Address localhost:1099 is already in use:tomcat频繁重启端口占用问题
错误提示
Unable to open debugger port (127.0.0.1:58198): java.net.SocketException "Socket closed"
Address localhost:1099 is already in use
端口被占用 报错原因 由于短时间内频繁运行tomcat服务器。 为了避免出现这一错误。可以点击刷新uodate resourc…

vulhub GhostScript 沙箱绕过(CVE-2018-16509)
1.搭建环境 2.进入网站 3.下载包含payload的png文件
vulhub/ghostscript/CVE-2018-16509/poc.png at master vulhub/vulhub GitHub 4.上传poc.png图片 5.查看创建的文件
Windows自动化程序开发指南
自动化程序的概念
“自动化程序”指的是通过电脑编程来代替人类手工操作的一类程序或软件。这类程序具有智能性高、应用范围广的优点,但是自动化程序的开发难度大、所用技术杂。
本文对自动化程序开发的各个方面进行讲解。 常见的处理对象
自动化程序要处理的对…

海外合规|新加坡网络安全认证计划简介(一)
新加坡网络安全局(CSA)为组织制定了网络安全认证计划,旨在表彰具有良好网络安全实践的组织。Cyber Essentials 标志表彰已实施网络卫生措施的组织,而 Cyber Trust 标志则是表彰具有全面网络安全措施和实践的组织的卓越标志。这些标…


【数据结构】顺序表的应用
基于动态顺序表实现通讯录
功能要求
1)至少能够存储100个⼈的通讯信息 2)能够保存用户信息:名字、性别、年龄、电话、地址等 3)增加联系人信息 4)删除指定联系人 5)查找制定联系人 6)修改指定…
HMI设计:嵌入式设备和电脑的差异化,工控领域首选。
嵌入式设备属于专机专用,电脑是通用,从性能、用途、特殊能力、成本、通信上嵌入式设备完全优于电脑,是工控领域的首选。
嵌入式设备和电脑在很多方面有着显著的差异,主要体现在以下几个方面:
1. 设计用途:…

深入理解C代码中的条件编译
引言
条件编译是 C 编程中的一个重要特性,它允许开发人员根据不同的条件选择性地编译源代码的不同部分。这一特性对于编写跨平台的程序、优化代码性能或控制编译时资源消耗等方面非常重要。本文将深入探讨条件编译的工作原理、使用场景、高级应用以及注意事项&…

# VMware 共享文件
VMware tools快速安装
VMware 提供了 open-vm-tools,这是 VMware 官方推荐的开源工具包,通常不需要手动安装 VMware Tools,因为大多数 Linux 发行版(包括 Ubuntu、CentOS 等)都包含了 open-vm-tools,并且已…

Leetcode面试经典150题-69.X的平方根
相当简单的题目,但是出现的概率还挺高的
解法都在代码里,不懂就留言或者私信
class Solution {public int mySqrt(int x) {/**0的平方根是0 */if(x 0) {return 0;}/**1~3的平方根是1 */if(x < 3) {return 1;}/**其他情况我们采用二分查找ÿ…

vscode从本地安装插件
1. 打开VSCode。 2. 点击左侧菜单中的“扩展”(或按CtrlShiftX)。 3. 点击“更多操作”(三个点)> “从VSIX安装”。 4. 选择下载的.vsix文件。 5. 点击“安装”即可安装插件。