本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/439868.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

一文梳理RAG(检索增强生成)的现状与挑战
一 RAG简介
大模型相较于过去的语言模型具备更加强大的能力,但在实际应用中,例如在准确性、知识更新速度和答案透明度方面,仍存在不少问题,比如典型的幻觉现象。因此,检索增强生成 (Retrieval-Augmented Generation, …

猫眼电影字体破解(图片转码方法)
问题 随便拿一篇电影做样例。我们发现猫眼的页面数据在预览窗口中全是小方框。在当我们拿到源码以后,数据全是加密后的。所以我们需要想办法破解加密,拿到数据。 破解过程 1.源码获取问题与破解 分析 在我们刚刚请求url的时候是可以得到数据的ÿ…
『功能项目』主角身旁召唤/隐藏坐骑【20】
本章项目成果展示 我们打开上一篇19坐骑UI搭建及脚本控制显/隐的项目, 本章要做的事情是在坐骑UI界面点击召唤及隐藏坐骑的功能
首先在外包中拖拽一个坐骑熊的预制体 完全解压缩 重命名为MountBear 在资源文件夹Resources下的/预制体文件夹Prefabs下新建坐骑文件夹…

HUAWEI华为MateBook B5-420 i5 集显(KLCZ-WXX9,KLCZ-WDH9)原装出厂Windows10系统文件下载
适用型号:KLCZ-WXX9、KLCZ-WDH9
链接:https://pan.baidu.com/s/12xnaLtcPjZoyfCcJUHynVQ?pwdelul 提取码:elul
华为原装系统自带所有驱动、出厂主题壁纸、系统属性联机支持标志、系统属性专属LOGO标志、华为浏览器、Office办公软件、华为…

基于SpringBoot的图书馆座位预约系统+小程序+LW参考示例
系列文章目录 1.基于SSM的洗衣房管理系统原生微信小程序LW参考示例 2.基于SpringBoot的宠物摄影网站管理系统LW参考示例 3.基于SpringBootVue的企业人事管理系统LW参考示例 4.基于SSM的高校实验室管理系统LW参考示例 5.基于SpringBoot的二手数码回收系统原生微信小程序LW参考示…


【计算机网络】TCP协议(下)
上篇我们介绍了三次握手四次挥手,这次继续来进行tcp的介绍。
1 TINE_WAIT与CLOSE_WAIT 我们先使用客户端作为左端,服务端作为右方 当我们客户端close时,就会发起两次挥手,此时服务端就会进入CLOSE_WAIT状态,只要服务端…

【Prometheus】Prometheus安装部署流程详解,配置参数webUI使用方法解析说明
✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…

Vivado编译报错黑盒子问题
1 问题描述 “Black Box Instances: Cell **** of type ** has undefined contents and is considered a back box. The contents of this cell must be defined for opt_design to complete successfully.” 检查工程代码提示的模块,该模块为纯手写的Veril…

一个基于Spring实现的热更新插件开发框架
前言
对于其他解释性语言来说,热更新根本不是什么事,但对于Java来说是多么的不容易,现在使用Java开发的热更新系统,基本使用JS编写脚本,然后用Java的JavaScript引擎来跑脚本。
spring-hot-plugin
现在有一款开源的S…

无人机人工增雨技术详解
无人机,全称为无人驾驶飞行器(Unmanned Aerial Vehicle, UAV),是一种不需要人员直接操控,而是利用先进的遥控技术、自主飞行控制系统和传感器技术来实现空中飞行和完成特定任务的飞行器。 一、技术原理
无人机人工增雨…

【MySQL】MySQL Workbench下载安装、环境变量配置、基本MySQL语句、新建Connection
1.MySQL Workbench 下载安装:
进入网址:MySQL :: MySQL Workbench Manual :: 2 Installation (1)点击“MySQL Workbench on Windows”(下载Windows版本)(2)点击“Installing” &…

春日美食汇:基于SpringBoot的订餐平台
2 系统关键技术 2.1JSP技术 JSP(Java脚本页面)是Sun和许多参与建立的公司所提倡的动态web技术。将Java程序添加到传统的web页面HTML文件()。htm,。Html) [1]。 JSP这种能够独立使用的编程语言可以嵌入在html语言里面运行,正因为JSP参照了许多编程语言的特性…

实验八 输入/输出流
实验目的及要求
目的:通过实验掌握java提供的输入/输出包中类的使用,特别是一些常用的类的方法的使用,运用流的概念实现对象的序列化。
要求:
(1)编写程序使用BufferedReader和BufferedWriter对文件进行…

恶意代码分析-Lab01-01
实验一 这个实验使用Lab01-01.exe和Lab01-01.d文件,使用本章描述的工具和技术来获取关于这些文件的信息。 问题:
将文件上传至 http:/www.VirusTotal.com/进行分析并查看报告。文件匹配到了已有的反病毒软件特征吗?这些文件是什么时候编译的?这两个文件中是否存在迹象说明它…

iOS——方法交换Method Swizzing
什么是方法交换
Method Swizzing是发生在运行时的,主要用于在运行时将两个Method进行交换,我们可以将Method Swizzling代码写到任何地方,但是只有在这段Method Swilzzling代码执行完毕之后互换才起作用。 利用Objective-C Runtimee的动态绑定…

【Qt】qt发布Release版本,打包.exe可执行文件
前言:Qt编译的可执行程序,如果直接运行,会出现0xc000007b报错,或者“由于占不到Qt5Network.dll,无法继续执行代码。重新安装程序可能会解决此问题”的报错,因为缺少相关的依赖包和动态库。
1、第一步:找到…
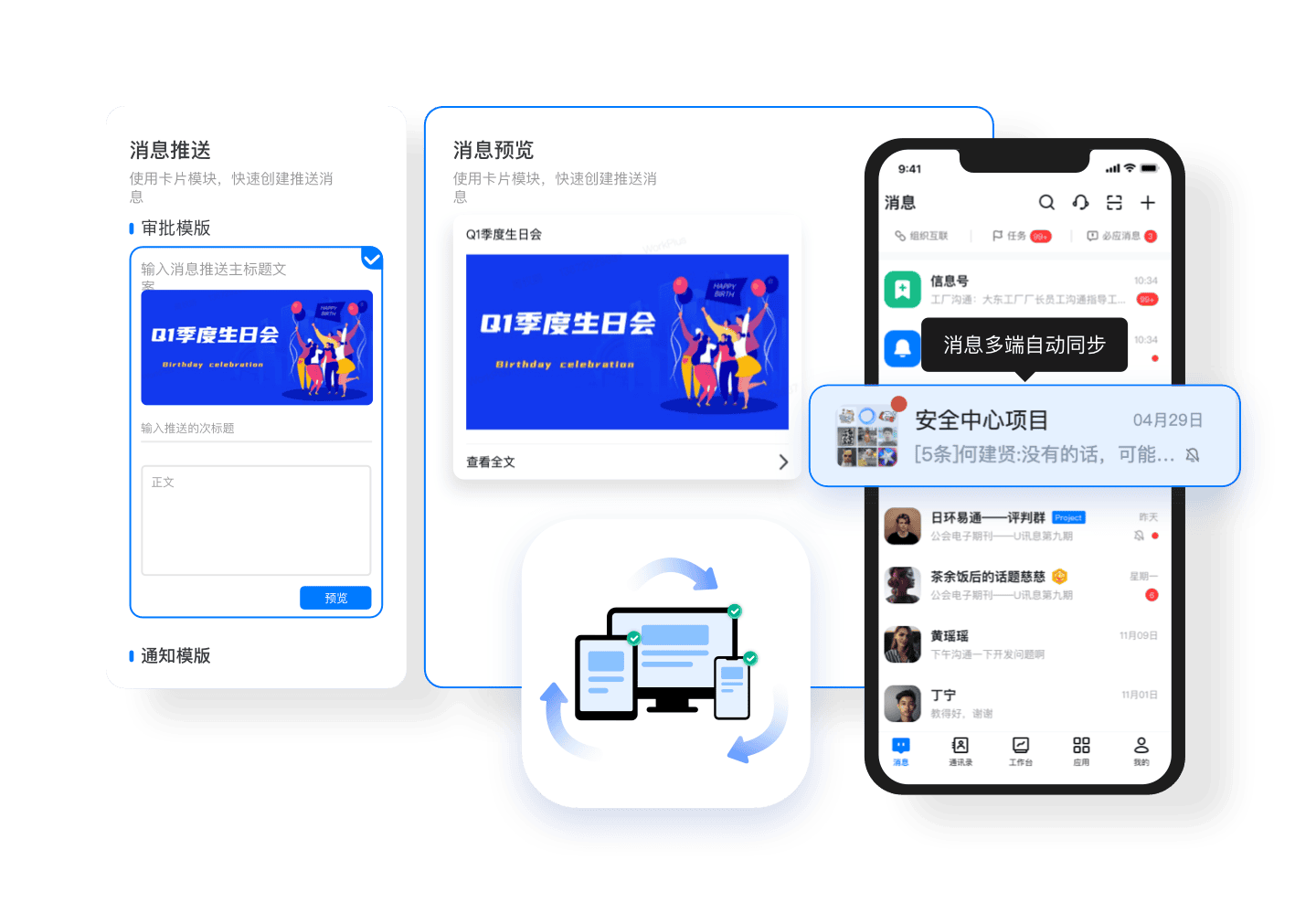
IM即时通讯软件-WorkPlus私有化部署的局域网即时通讯工具
随着企业对通讯安全和数据掌控的需求不断增加,许多企业开始选择私有化部署的即时通讯工具,以在内部局域网环境中实现安全、高效的沟通与协作。IM-WorkPlus作为一款受欢迎的即时通讯软件,提供了私有化部署的选项,使企业能够在自己的…
![[数据集][目标检测]轮胎检测数据集VOC+YOLO格式4629张1类别](https://i-blog.csdnimg.cn/direct/2857c086fdc44da29d3c36213fc10cd6.png)
[数据集][目标检测]轮胎检测数据集VOC+YOLO格式4629张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):4629 标注数量(xml文件个数):4629 标注数量(txt文件个数):4629 标注…

用Boot写mybatis的增删改查
一、总览
项目结构: 图一
1、JavaBean文件 2、数据库操作 3、Java测试 4、SpringBoot启动类
5、SpringBoot数据库配置 二、配置数据库
在项目资源包中新建名为application.yml的文件,如图一。
建好文件我们就要开始写…