本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/439989.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

原型模式prototype
此篇为学习笔记,原文链接 https://refactoringguru.cn/design-patterns/prototype
能够复制已有对象, 而又无需使代码依赖它们所属的类
所有的原型类都必须有一个通用的接口, 使得即使在对象所属的具体类未知的情况下也能复制对象。 原型对…

ubuntu上通过openvswitch卸载实现roce over vxlan
环境
操作系统:
uname -a
Linux 5.4.0-187-generic #207-Ubuntu SMP Mon Jun 10 08:16:10 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux Mellanox网卡:
ethtool -i ens6np0
driver: mlx5_core
version: 23.10-2.1.3
firmware-version: 20.39.3004 (MT_0…

FreeRTOS实战指南 — 1 FreeRTOS简介
目录
1.1 为什么需要FreeRTOS
1.2 FreeRTOS资料获取
1.3 FreeRTOS文件夹内容 1.1 为什么需要FreeRTOS
裸机开发直接控制硬件,虽然资源占用少,但开发复杂性高,缺乏高级功能,适合资源受限的简单应用。嵌入式操作系统提供了硬件抽…

工厂ERP管理系统实现源码(JAVA)
工厂进销存管理系统是一个集采购管理、仓库管理、生产管理和销售管理于一体的综合解决方案。该系统旨在帮助企业优化流程、提高效率、降低成本,并实时掌握各环节的运营状况。 在采购管理方面,系统能够处理采购订单、供应商管理和采购入库等流程ÿ…

TitleBar:打造高效Android标题栏的新选择
在Android应用开发中,标题栏是用户界面的重要组成部分。一个好的标题栏不仅能够提升应用的专业感,还能增强用户体验。然而,传统的标题栏实现方式往往存在代码冗余、样式不统一、性能开销大等问题。今天,我们将介绍一个名为TitleBa…

数据结构与算法03 顺序表+链表
注意点:
函数的定义中建议增加断言:结构体指针不能为NULL!(空指针不能接引用!)控制台退出后显示的代码只要不为0,就不是正常退出!Vs中编辑 -> 高级 -> 查看空白 可以…
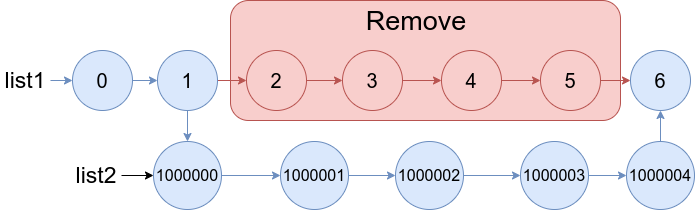
【数据结构与算法 | 灵神题单 | 删除链表篇】力扣3217, 82, 237
总结,删除链表节点问题使用到列表,哈希表,递归比较容易超时,我觉得使用计数排序比较稳,处理起来也不是很难。 1. 力扣3217:从链表中移除在数组中的节点
1.1 题目:
给你一个整数数组 nums 和一…

SprinBoot+Vue漫画天堂网的设计与实现
目录 1 项目介绍2 项目截图3 核心代码3.1 Controller3.2 Service3.3 Dao3.4 application.yml3.5 SpringbootApplication3.5 Vue 4 数据库表设计5 文档参考6 计算机毕设选题推荐7 源码获取 1 项目介绍 博主个人介绍:CSDN认证博客专家,CSDN平台Java领域优质…

mysql笔记4(数据类型)
数据库的数据类型应该是数据库架构师(DBA)和产品经理沟通后依据公司的项目、业务而定的,而且会不停地变化。数据类型的选择方面没有一个统一的标准,但是应该符合业务、项目的逻辑标准。 菜鸟教程 Mysql 数据类型 文章目录 1. int类型2. 浮点数3. 定点数4…

【音视频】播放音视频时发生了什么? 视频的编解码 H264是什么? MP4是什么?
目录 ✨播放一个视频的流程✨为什么要编码(压缩)视频数据?✨如何编码(压缩)数据🎄简单的例子🎄音视频编码方式🎄视频编码格式H264编码是什么?发展历程?H.264基…
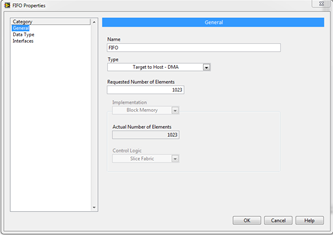
LabVIEW FIFO详解
在LabVIEW的FPGA开发中,FIFO(先入先出队列)是常用的数据传输机制。通过配置FIFO的属性,工程师可以在FPGA和主机之间,或不同FPGA VIs之间进行高效的数据传输。根据具体需求,FIFO有多种类型与实现方式&#x…
在OpenEuler(欧拉)系统上用kubeadm部署(k8s)Kubernetes集群
一、OpenEuler(欧拉) 系统简介
openEuler 是开放原子开源基金会(OpenAtom Foundation)孵化及运营的开源项目;
openEuler作为一个操作系统发行版平台,每两年推出一个LTS版本。该版本为企业级用户提供一个安全稳定可靠的操作系统。…

语音识别转文字工具:办公效率的得力助手
从古老的文字记载到现代的即时通讯,技术的每一次飞跃都极大地丰富了人类信息传递的维度。而在这股技术浪潮中,语音识别转文字工具无疑成为了连接语音与文字、促进高效沟通的桥梁。这次我们就来探索有那些可以方便我们转化语音的工具。
1.365在线转文字 …

word快速编写公式
1. 截图识别公式
Kimi官网 这里Kimi给出的公式如下
\begin{align}
G_{r}\left[I_{in}(i, j) - I_{in}(m, n)\right] \exp\left\{-\frac{\left[I_{in}(i, j) - I_{in}(m, n)\right]^{2}}{2\sigma_{r}^{2}}\right\}
\end{align}2. katex公式转换word
在线工具网页 完成3个步…

免费也能高质量!2024年免费录屏软件深度对比评测
我公司因为客户覆盖面广的原因经常会开远程会议,有时候说的内容比较广需要引用多份的数据,我记录起来有一定难度,所以一般都用录屏工具来记录会议内容。这次我们来一起探索有什么免费录屏工具可以提高我们的工作效率吧。
1.福晰录屏大师
链…


webpack - 五大核心概念和基本配置(打包一个简单HTML页面)
// 五大核心概念
1. entry(入口)
指示Webpack从哪个文件开始打包2. output(输出)
指示Webpack打包完的文件输出到哪里去,如何命名等3. loader(加载器)
webpack本身只能处理js,json等…



A02、Java编程性能调优(02)
1、Stream如何提高遍历集合效率
1.1、什么是Stream 现在很多大数据量系统中都存在分表分库的情况。例如,电商系统中的订单表,常常使用用户 ID 的 Hash 值来实现分表分库,这样是为了减少单个表的数据量,优化用户查询订单的速度。 …