本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/440068.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

虚拟现实智能家居实训系统实训解决方案
随着科技的飞速发展,智能家居已成为现代生活的重要组成部分,它不仅极大地提升了居住的便捷性与舒适度,还推动了物联网、大数据、人工智能等前沿技术的融合应用。为了满足市场对智能家居专业人才日益增长的需求,虚拟现实智能家居实…

《数字信号处理》学习05-单位冲击响应与系统响应
目录
一,单位冲激响应
二,LTI系统对任意序列的系统响应 三,LTI系统的性质 通过上一篇文章《数字信号处理》学习04-离散时间系统中的线性时不变系统-CSDN博客的学习,我已经知道了离散时间线性时不变系统(LTI&#x…

铝材的知识与应用,基础全面
铝的基本性质
银白色,在潮湿的空气中能形成一层防止金属腐蚀的氧化膜,相对密度2.7g/cm3,熔点660℃,沸点2327℃,比强度较高,有良好的导电性和导热性,高反射性和耐氧化性。 二、种类
型材类&…
![[ios]准备好app后使用xcode发布ios操作](https://i-blog.csdnimg.cn/direct/2c5a0c30fe30452eb7c34cf208231946.png)
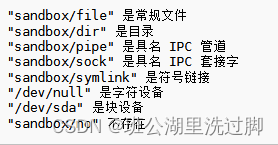
标准库标头 <filesystem> (C++17)学习之文件类型
本篇介绍filesystem文件库的文件类型API。 文件类型 is_block_file (C17) 检查给定的路径是否表示块设备 (函数) is_character_file (C17) 检查给定的路径是否表示字符设备 (函数) is_directory (C17) 检查给定的路径是否表示一个目录 (函数) is_empty (C17) 检查给定的路径是…

VMware Fusion Pro 13 Mac版虚拟机 安装Win11系统教程
Mac分享吧 文章目录 Win11安装完成,软件打开效果一、VMware安装Windows11虚拟机1️⃣:准备镜像2️⃣:创建虚拟机3️⃣:虚拟机设置4️⃣:安装虚拟机5️⃣:解决连不上网问题 安装完成!࿰…

港科夜闻 | 叶玉如校长出席2024科技+新质生产力高峰论坛发表专题演讲,贡献国家科技强国战略...
关注并星标 每周阅读港科夜闻 建立新视野 开启新思维 1、叶玉如校长出席“2024科技新质生产力高峰论坛”,做了题为“三个创新:培育和发展新质生产力、贡献国家科技强国战略”的主题演讲。该论坛于9月2日在香港召开。论坛围绕夯实基础科研、推动源头创新、…
打造安心宠物乐园:EasyCVR平台赋能猫咖/宠物店的智能视频监控解决方案
随着宠物经济的蓬勃发展,宠物店与猫咖等场所对顾客体验、宠物安全及健康管理的需求日益提升。然而,如何确保这些场所的安全与秩序,同时提升顾客体验,成为了经营者们关注的焦点。引入高效、智能的视频监控方案,不仅能够…

微信企业微信忽然爆满 怎么清理才干净?一招彻底清理干净垃圾文件
大家都知道,微信用久了就会堆积很多的垃圾,然后导致系统空间不足,继而引发一些不必要的系统问题,所以清理掉这些垃圾是有必要的。今天我们就给大家介绍一个可以清理微信和企业微信的工具。
解决微信&企业微信忽然爆满的步骤&…

PMP–一、二、三模–分类–14.敏捷–技巧–变革就绪情况
文章目录 技巧一模14.敏捷–组织考虑因素--变革就绪情况--管理层的变更意愿,是组织是否变革就绪的重要前提。答案关键字,获得支持107、 [单选] 一家沉浸于传统瀑布式项目管理中的PMO聘请了你,作为敏捷实践者,来指导组织向敏捷的转…

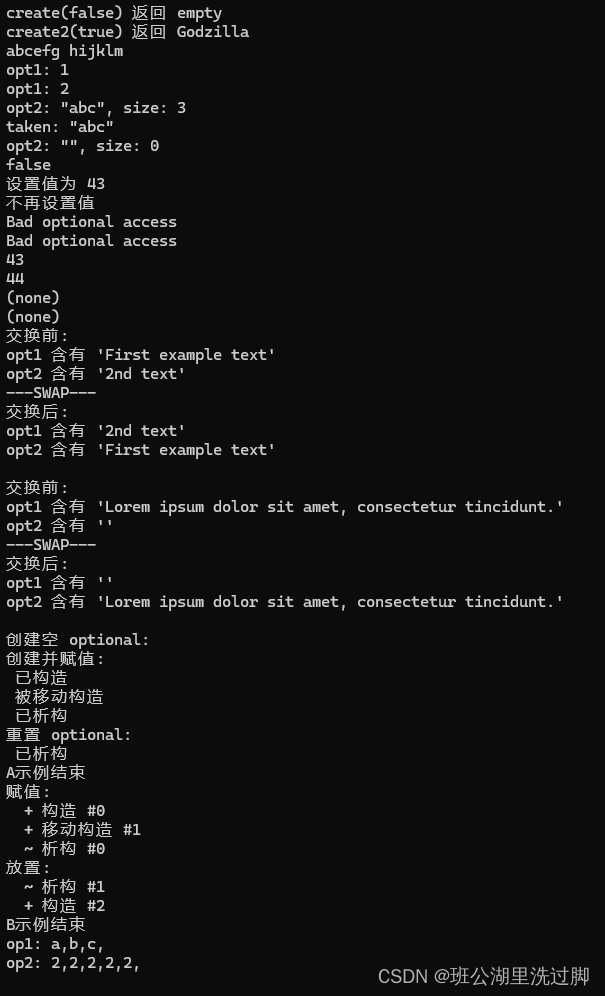
标准库标头 <optional> (C++17)学习之optional
类模板 std::optional 管理一个可选 的所含值,即既可以存在也可以不存在的值。
一种常见的 optional 使用情况是作为可能失败的函数的返回值。与如 std::pair<T, bool> 等其他手段相比,optional 可以很好地处理构造开销高昂的对象&a…

数据库的操作:SQL语言的介绍
一.前言
SQL是一种结构化查询语言。关系型数据库中进行操作的标准语言。
二.特点
①对大小写不敏感
例如:select与Select是一样的
②结尾要使用分号 没有分号认为还没结束;
三.分类
①DDL:数据定义语言(数据库对象的操作(结…

通义千问更新数学大模型及视觉多模态
Qwen2-Math,这是通义千问专门为数学场景优化的模型,其数学能力指标甚至超越了GPT4o, Claude3.5 Sonnet, Deepseek Coder等顶流模型,目前从指标来看是最强的数学模型。目前是免费供应,大家碰到数学问题可以选择使用这个模型。 Qw…

开放式耳机对耳朵伤害大吗?超舒适开放式耳机推荐!
开放式耳机通常被认为对耳朵的伤害相对较小。这种耳机的设计不深入耳道,允许空气流通,减少了耳道内潮湿和细菌滋生的风险,同时也降低了因耳道封闭造成的不适和炎症可能性。开放式耳机的佩戴方式通常更为舒适,减少了对耳道的摩擦和…
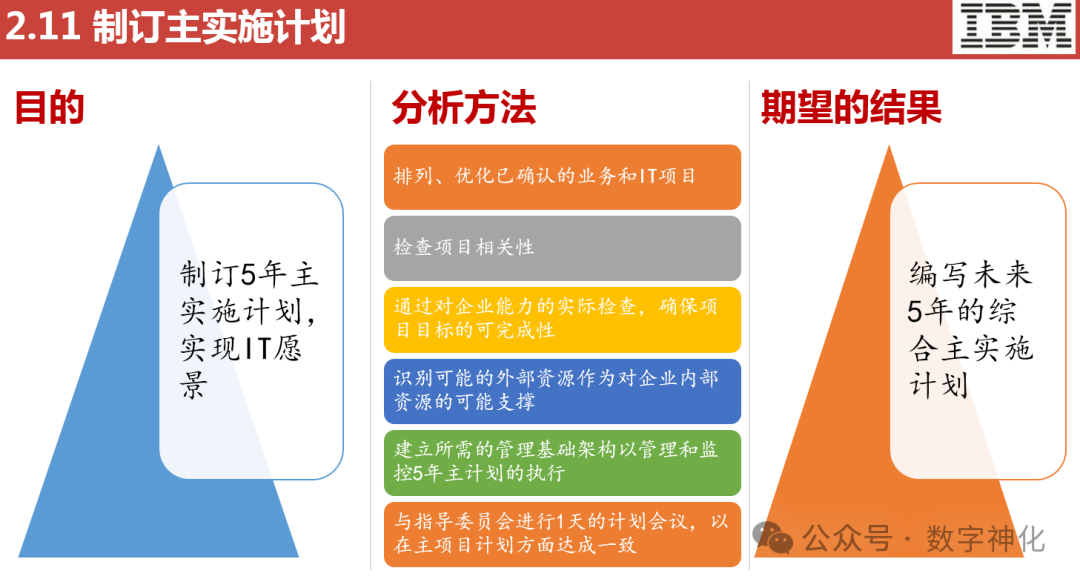
数字化转型的战略规划应该怎么做?(附IBM-IT战略规划方法论PPT下载)
IBM-IT战略规划方法论PPT-下载链接见文末~
数字化转型的战略规划是一个系统而复杂的过程,需要从多个维度进行考虑和规划。以下是一些关键步骤和建议,以帮助企业制定有效的数字化转型战略规划:
1. 明确数字化转型愿景和目标
设定愿景&#…

AI大模型微调技术:AI全栈大模型项目实战,人工智能视,多模态大模型
AI大模型微调技术:解锁迁移学习的潜力
在人工智能领域,大模型微调技术正逐渐崭露头角,成为迁移学习中的一项重要技术。本文将深入探讨AI大模型微调技术的原理、方法以及其在实际应用中的潜力。
一、微调技术的概念与原理…

解决el-table中使用el-input无法聚焦问题
在el-table中点击单元格时使用el-input或其他表单组件编辑单条数据。会出现聚焦不上的问题,需要手动点击才能够聚焦。究其原因是因为点击单元格时页面已自动聚焦到单元格,此时无法自动聚焦到对应的表单,需要手动设置。 <template><e…

ICM20948 DMP代码详解(9)
接前一篇文章:ICM20948 DMP代码详解(8) 上一回解析完了EMP-App中的入口函数main()中重点关注的第2段代码,本回继续往下解析。为了便于理解和回顾,在此贴出main函数代码,如下:
int main (void)
…

UE5 Linux编译流程(实战)
文章目录 概述setup.sh2.GenerateProjectFiles.sh3.make其他的 小结 概述
之前写过一篇linux上代码的流程,这一篇,补下编译流程。4.26还是4.27的时候,做过编译,那会刚出来,当时编译用的是QT,跟着文档&…