本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/440158.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

fpga入门名词(1)
这是第一代FPGA
,在 FPGA(现场可编程门阵列)设计中,LCA(逻辑单元阵列)通常由几个关键组件构成,包括 IOB、CLB 和 Interconnect。以下是这些组件的简要说明:
1. IOB(Input/Output B…

【redis】本地windows五分钟快速安装redis
用处:本地自测,有时候公司redis环境不稳定,用自己的
1.下载,github下载一个解压缩在自己想要的位置
选择版本:Redis-7.4.0-Windows-x64-msys2-with-Service,zip
GitHub - redis-windows/redis-windows: …

YOLOv9模型训练或测试过程中,无法打印模型的GFLOPs
项目场景:
在YOLOv9模型的改进中,常常需要替换一些模块来提高模型的精度。但在评价模型大小规模的时候需要根据模型的参数量、计算量进行评定,一般在模型的训练文件train.py,或者是test.py还有models/yolo.py都会输出这些数据。 …

程序员日志之DNF编年史
目录 传送门正文日志1、概要2、超高度总结概括3、详细编年史3.1、大背景3.2、冒险家 传送门
SpringMVC的源码解析(精品) Spring6的源码解析(精品) SpringBoot3框架(精品) MyBatis框架(精品&…

sqlserver 如何收缩+最大化压缩数据库
zihao 直接运行即可
-- 最大化压缩数据库
USE [数据库名称]; -- 这里必须填写库名称
GO
EXEC sp_MSforeachtable ALTER TABLE ? REBUILD PARTITION ALL WITH (DATA_COMPRESSION PAGE);;-- 收缩数据库
DBCC SHRINKDATABASE (N数据库名称, 1); -- 这里必须填写库名称
GO
![[Python学习日记-12] 双色球彩票程序练习(使用到列表、判断、循环等)](https://i-blog.csdnimg.cn/direct/469cb1aa53014950bfd28f27b65c74f0.png)
[Python学习日记-12] 双色球彩票程序练习(使用到列表、判断、循环等)
[Python学习日记-12] 双色球彩票程序练习
简介
题目
答案与解析 简介 本章的练习将会使用到前面学习的知识点,用于检测前面学习的效果。
题目
双色球彩票选购程序:
先让用户依次选择6个红球,再选择2个蓝球,最后统一打印用户…
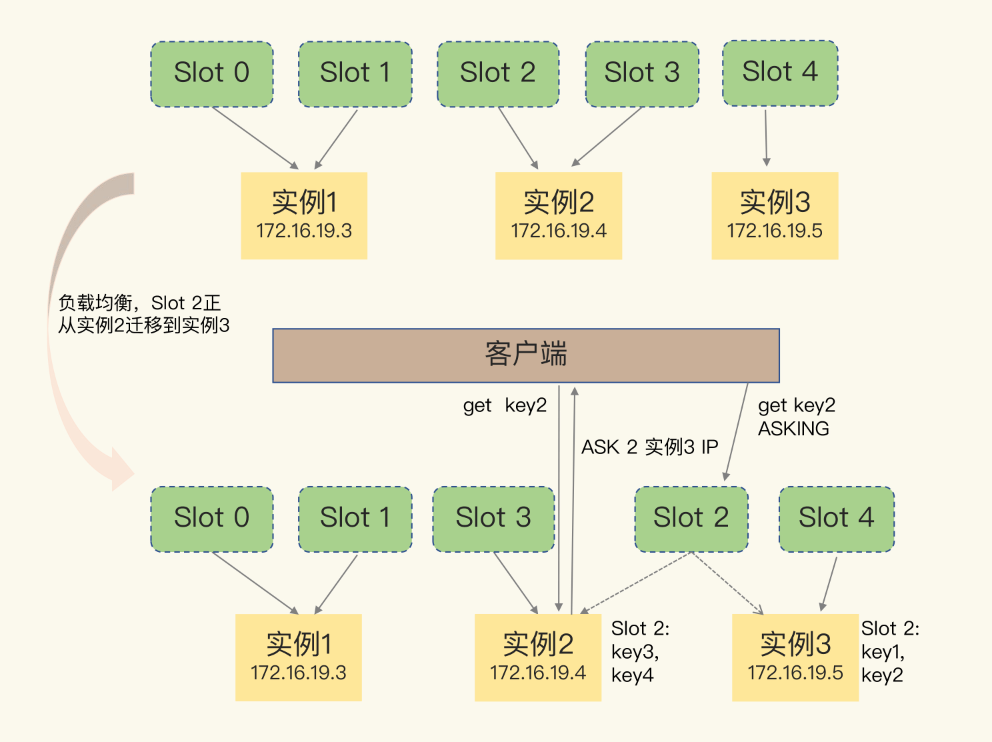
Redis 主从复制、切片集群
一、主从复制 1、主从关系 都说的 Redis 具有高可靠性,这里有两层含义:一是数据尽量少丢失,二是服务尽量少中断。AOF 和 RDB 保证了前者,而对于后者,Redis 的做法就是将一份数据同时保存在多个实例上。为了保证数据一致…

提升交易成功率:三重滤网交易系统详解
经验丰富的交易者往往拥有一套个性化的交易系统,其系统通过明确的交易规则和策略,帮助他们更有效地管理风险,并借助量化交易行为与控制心态的手段,提升交易的效率和成功率。在众多交易系统中,有一种使用三重筛选方式来…

【云原生】docker 部署 Doris 数据库使用详解
目录 一、前言
二、数据分析概述
2.1 什么是数据分析
2.2 数据分析目的和意义
2.3 数据分析常用的技术和工具
2.3.1 编程语言
2.3.2 数据处理和分析库
2.3.3 数据可视化工具
2.3.4 数据库系统
2.3.5大数据处理框架
2.3.6 云服务和平台
2.3.7 其他工具
三、Doris介绍…

java编辑器——IntelliJ IDEA
java编辑器有两种选择——IntelliJ IDEA和VsCode。其中IntelliJ IDEA现在是企业用的比较多的,是专门为java设计的,而VsCode则是通过插件来实现Java编辑的。
1.IntelliJ IDEA
官网下载链接:https://www.jetbrains.com/idea/ 注意选择社区版…


AI 狂潮:引领未来变革,就业格局大洗牌
在科技飞速发展的今天,AI(人工智能)无疑是最受瞩目的领域之一。它正以惊人的速度改变着我们的生活,那么,AI 的未来发展趋势究竟会走向何方呢? 一、AI 在各个领域的深度融合
医疗领域 AI 在医疗领域的应用已…

2、PF-Net点云补全
2、PF-Net 点云补全
PF-Net论文链接:PF-Net PF-Net (Point Fractal Network for 3D Point Cloud Completion)是一种专门为三维点云补全设计的深度学习模型。点云补全实际上和图片补全是一个逻辑,都是采用GAN模型的思想来进行补全…

电力系统中的A类在线监测装置—APView400
随着电力系统的日益复杂和人们对电能质量要求的提高,电能质量在线监测装置在电力系统中得到广泛应用。目前,市场上的在线监测装置主要分为A类和B类两种类型,A类和B类在线监测装置主要区别在于应用场景、技术参数、通讯协议和扩展性。选择时应…

u盘数据恢复篇:U盘损坏怎么恢复里面的数据?6种方法即刻恢复
u盘里误删的文件去哪了?什么数据恢复的方法最好?今天我要和大家分享一些关于如何恢复损坏U盘中的数据的方法。U盘是我们日常生活中经常使用的便携存储设备,但是有时候因为各种原因,比如意外删除、格式化、物理损坏等,会…

2024全开源彩虹晴天多功能系统源码/知识付费系统/虚拟商城系统 完美可用带教程
源码简介:
2024最新彩虹晴天多功能系统源码,知识付费虚拟商城,完美可用,无需授权、国内外服务器皆可搭建、无论是不是备案域名也都可以部署、可以商业运营。
这个源码实用,它不仅完美可用,而且完全免F&am…

缺陷就是Bug?对了,但没完全对……
我叫缺陷,从被创建至关闭,到最后做缺陷分析,这是我的完整生命周期。我的整个生命周期贯穿着整个项目的项目周期,因此,掌握我的生命周期,不止是测试人员必修的课程,也是测试人员的灵魂。
缺陷的…

Error mongodb connect: 使用Mongoose连不上mongodb官方数据库
起因
使用mongoose官方文档的connect连Mongodb cloud免费数据库,始终连不上
await mongoose.connect(mongodb://127.0.0.1:27017/test);就一句代码,一个api,一个url多简单。死活连不上,困扰了我好久。 原本一开始我没有用mongoo…

【项目功能扩展】在线网站 -用户管理功能(用户注册登录修改等、利用cookie存储用户会话状态)
文章目录 0. 前言开发环境 & 涉及技术 1. 宏观结构2. 后端部分① sqlite 管理类② user 管理类 3. 前端部分(与后端交互)① 登录② 注册③ 查看登录用户的信息④ 更新用户信息⑤ 登出用户 & 注销用户注意 效果演示 0. 前言
源码链接:…