本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/440204.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

Self Refine技术测评:利用Self Refine提高LLM的生成质量
1. 背景与挑战
在当今人工智能蓬勃发展的时代,大型语言模型(Large Language Models,简称 LLMs)已成为众多企业不可或缺的核心技术。从智能客服到内容创作,LLMs 在各个领域都展现出了惊人的能力。然而,随着…

电机驱动及编码器测速(基于STM32F103C8T6HAL库)
硬件:STM32F103C8T6、电机驱动模块tb6612、25GA370带编码器测速盘直流减速电机。 1.电机驱动
1.1 电机驱动模块tb6612
(1)电机驱动模块tb6612简介
电机驱动需要使用电机驱动模块,电机驱动模块把3.3V的电机信号转换成12V的电机的…

【MySQL00】【 杂七杂八】
文章目录 一、前言二、MySQL 文件1. 参数文件2. 日志文件3. 套接字文件4. pid 文件5. 表结构定义文件6. InnoDB 存储引擎文件 二、BTree 索引排序三、InnoDB 关键特性1. 插入缓冲1.1 Insert Buffer 和 Change Buffer1.1 缓冲合并 2. 两次写2. 自适应哈希索引3. 异步IO4. 刷新邻…

FuTalk设计周刊-Vol.073
#AI漫谈 热点捕手
1.Midjourney 样式分享网站
群里设计师创建的 Midjourney 风格网站,用来收集高质量 Sref Codes,展示示例图并且展示风格关键词,使用场景,以及示例提示词,作者称会持续更新
链接https://aiartsecre…

欧拉下搭建第三方软件仓库—docker
1.创建新的文件内容
切换目录到etc底下的yum.repos.d目录,创建docker-ce.repo文件
[rootlocalhost yum.repos.d]# cd /etc/yum.repos.d/
[rootlocalhost yum.repos.d]# vim docker-ce.repo
编辑文件,使用阿里源镜像源,镜像源在编辑中需要单独复制
h…

【C语言必学知识点七】什么?还有人不知道什么是柔性数组?还不速来!!!
动态内存管理——详细解读柔性数组 导读一、什么是柔性数组二、柔性数组的特点三、柔性数组的使用四、柔性数组的优势结语 导读
大家好,很高兴又和大家见面啦!!!
在上一篇内容中我们介绍了C/C程序中的内存分区,在C/C…
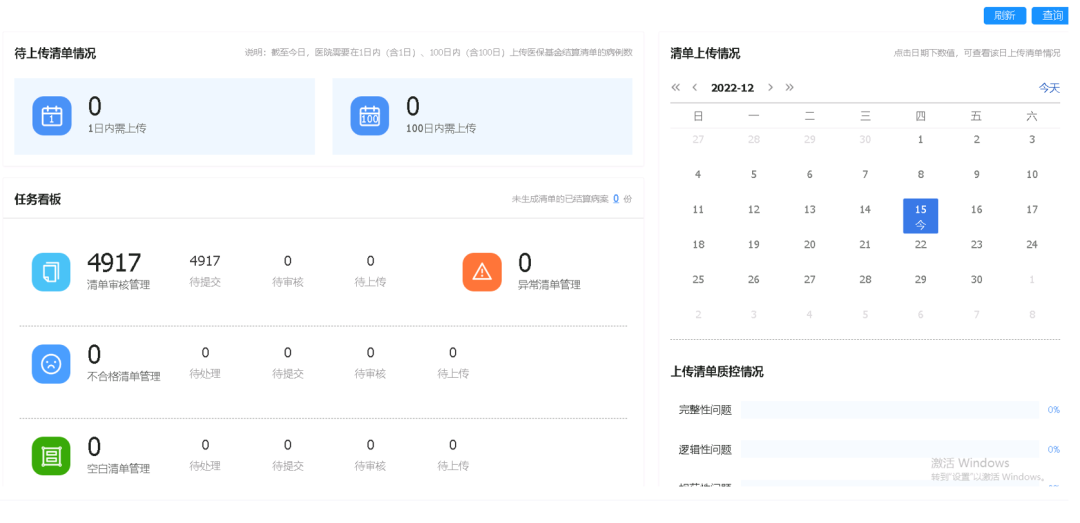
医疗机构关于DIP/DRG信息化建设
推进DIP/DRG支付方式改革是一项系统性工程,牵一发而动全身。作为河北省DIP试点医院,河北医科大学第二医院将信息化与创新性管理理念融合,用好支付工具做好精细化管理,积极应对改革。 ■ 改革背景
国家医疗保障局制定的《DRG/DIP支…

【北京迅为】《STM32MP157开发板使用手册》- 第十二章 编译Linux内核
iTOP-STM32MP157开发板采用ST推出的双核cortex-A7单核cortex-M4异构处理器,既可用Linux、又可以用于STM32单片机开发。开发板采用核心板底板结构,主频650M、1G内存、8G存储,核心板采用工业级板对板连接器,高可靠,牢固耐…

Spring Boot项目中集成JWT进行身份验证
什么是JWT?
JWT(JSON Web Token)是一种开放标准(RFC 7519),用于在网络应用环境中安全地传递信息。它主要用于在客户端和服务器之间传递经过签名的 JSON 数据,以确保数据的完整性和真实性。
1.JWT 的结构…

Excel--复制粘贴时怎么跳过隐藏的行和列
方法一
比如如何跳过下面的行复制其他 首先将黄色的背景行按CTRL0隐藏起来 打开定位条件 选择可见单元格,点击确定 然后复制表格粘贴即可
方法二
首先将不需要的行和列隐藏起来,按Alt;锁定可见单元格。 复制粘贴即可,这样粘贴的…


数学建模常见模型(下)
目录
神经网络法详细介绍
1. 引言
2. 神经网络的基本概念
2.1 神经元
2.2 层次结构
2.3 激活函数
3. 神经网络的工作原理
3.1 前向传播
3.2 反向传播
4. 神经网络的类型
4.1 前馈神经网络(Feedforward Neural Networks, FNN)
4.2 卷积神经网…
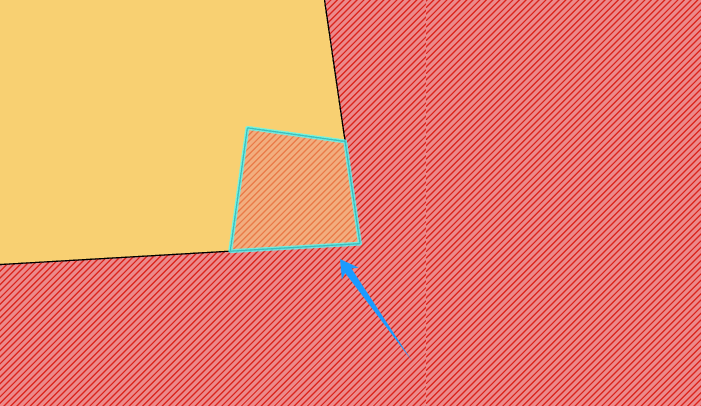
ArcGIS小技巧:图斑变化分析
在做规划的过程中,经常会有这么个需求,用地方案确定后,需求找出规划用地和三调现状用地之间具体有哪些变化。
一方面可以用作具体规划内容的分析,另一方面也可以避免因为误操作而导致的错误图斑的出现。
以下图为例,…

D 咖智能饮品机器人:科技与美味共舞,奏响饮品新乐章
在科技飞速发展的时代浪潮中,D 咖智能饮品机器人如一颗璀璨的新星闪耀登场,以其独特的魅力将科技与美味完美融合,奏响了饮品世界的新乐章。 当你第一次邂逅 D 咖智能饮品机器人,便会被它那充满未来感的外观所吸引,锃亮…

民生水暖工程背后的科技力量引领工程智能化转型
物联网技术的广泛应用,使得物理设备能够实时传输运行状态数据至云端,实现了设备的全面感知与互联互通。每一台机器、每一个传感器都成为数据的源泉,为远程监控提供了坚实的基础。而大数据分析技术的应用,则让这些海量数据得以被高…

大数据决策分析平台建设方案(可编辑的56页PPT)
引言:在当今信息爆炸的时代,大数据已成为企业决策制定、业务优化与市场洞察的重要驱动力。为了充分挖掘大数据的潜在价值,提升决策效率与精准度,构建一套高效、灵活、可扩展的大数据决策分析平台显得尤为重要。通过大数据分析平台…

Python QT实现A-star寻路算法
目录
1、界面使用方法
2、注意事项
3、补充说明 用Qt5搭建一个图形化测试寻路算法的测试环境。
1、界面使用方法
设定起点:
鼠标左键双击,设定红色的起点。左键双击设定起点,用红色标记。
设定终点:
鼠标右键双击…

力扣每日1题--2181.合并零之间的节点
问题 下面我会向大家介绍我的思考过程和解题思路
解题思路
首先,我们看问题提供给我们的提示部分。第一点给了我们节点的数目,第二点给了我们val的范围,而我们这道题是要让我们求和的问题,那么我们就应该估算一下我们数据的一个…

What is Node.JS and its Pros and Cons
What is Node.JS and its Pros and Cons
JavaScript is a client-side development tool.
Node.js is a server-side development tool. And it’s only a runtime environment based on Chrome V8 so we don’t write some code in Node.js. Pros:
JavaScript on a server …