本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/440301.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

易灵思FPGA开发(一)——软件安装
一、资料下载
VF-T20F256-深圳市奥唯思科技有限公司_FPGA图像开发_MIPI (szovs.com)
二、软件安装 安装USB下载器驱动 双击第一个.msi文件进行安装
奥唯思FPGA网盘汇总 (szovs.com) 下载Gtkwave软件
Android Fragment 学习备忘
1.fragment的动态添加与管理,fragment生命周期在后面小节:https://www.bilibili.com/video/BV1Ng411K7YP/?p37&share_sourcecopy_web&vd_source982a7a7c05972157e8972c41b546f9e4https://www.bilibili.com/video/BV1Ng411K7YP/?p37&share_…

利用深度学习实现验证码识别-3-ResNet18
在当今数字化时代,验证码作为一种重要的安全验证手段,广泛应用于各种网络场景。然而,传统的验证码识别方法往往效率低下,准确率不高。今天,我们将介绍一种基于 ResNet18 的验证码识别方法,它能够高效、准确…

SAP 查看历史库存MB5B显示ALV报表配置简介
SAP 查看历史库存MB5B显示ALV报表配置简介 业务场景后台配置前台重新执行操作业务场景
用户希望MB5B在查询历史库存的时候,能和ALV报表一样的格式显示,不要显示LIST ALV的格式 如下图
后台配置
路径:SPRO路径:物料管理->物料管理的常规设置->业务加载项:激活物料…

【鸿蒙】HarmonyOS NEXT星河入门到实战1-开发环境准备
目录
一、达成目标
二、鸿蒙开发环境准备
2.1 开发者工作下载
2.2 解压安装
2.3 运行配置安装node.js和SDK
2.4 开始创建第一个项目
2.5 预览
2.5.1 预览遇到的问题(报错) 2.5.2 修改内容查看预览
三、备用下载地址(如果下载是4.X版…

Google Play结算防掉单方案
我们公司的产品主要是出海产品,使用的是Google Play支付,但是在上线以后,经常有客诉,说支付以后,权益没有到账,于是对整个Google支付体系做了研究了一下。
我们的整个支付流程图大概如下: 其中后端参考的文档地址为:
https://developers.google.com/android-publishe…


On the Detection of Digital Face Manipulation
文章目录 Learning Self-Consistency for Deepfake Detection背景关键点贡献方法损失函数多种假脸数据集实验Learning Self-Consistency for Deepfake Detection
会议:CVPR 2020 作者:
背景
检测被操纵的人脸图像和定位被操纵的区域是至关重要的 三种面部伪造攻击类型: …

TMS320F28335芯片及使用介绍
1、简介
CPU性能的好坏不仅取决于主频大小,还需要看其整体架构集成性能、运算能力与指令体系。TMS320C2000系列DSP集微控制器和高性能 DSP 的特点于一身,具有强大的控制和信号处理能力,能够实现复杂的控制算法。TMS320C2000 系列DSP 片上整合了Flash存储器、快速的AD转换器…

ICAS英格尔认证为全球鞋业可持续发展,提出ESG绿色发展新路径
8月29日,第十二届全球鞋业可持续发展国际峰会在东莞开幕。为期两天的峰会汇聚了来自世界各地的知名品牌方和采购商,共同探讨鞋业绿色环保、新材料、新技术及可持续发展等热点话题。 作为ESG(环境、社会、治理)、双碳及城市可持续发…

【基于 Spring Boot 的二手交易平台】
构建一个基于 Spring Boot 的二手交易平台是一个涉及多个组件和技术栈的复杂项目。以下是一个基本的框架概述,可以帮助你开始搭建这样一个平台:
技术栈选择
Spring Boot: 用于快速开发 RESTful Web 服务。数据库: MySQL, PostgreSQL, 或其他关系型数据…

Oracle Linux 8.10安装Oracle19c(19.3.0)完整教程
安装前请仔细将文档通读一遍,安装过程中根据安装命令仔细核对,特别留意一些字体加粗或标红的字样,遇到问题请及时咨询公司 1、基础环境
1.1、操作系统
cat /etc/redhat-release 1.2、主机名
医院默认分配的主机名可能跟其他主机会有重复&a…
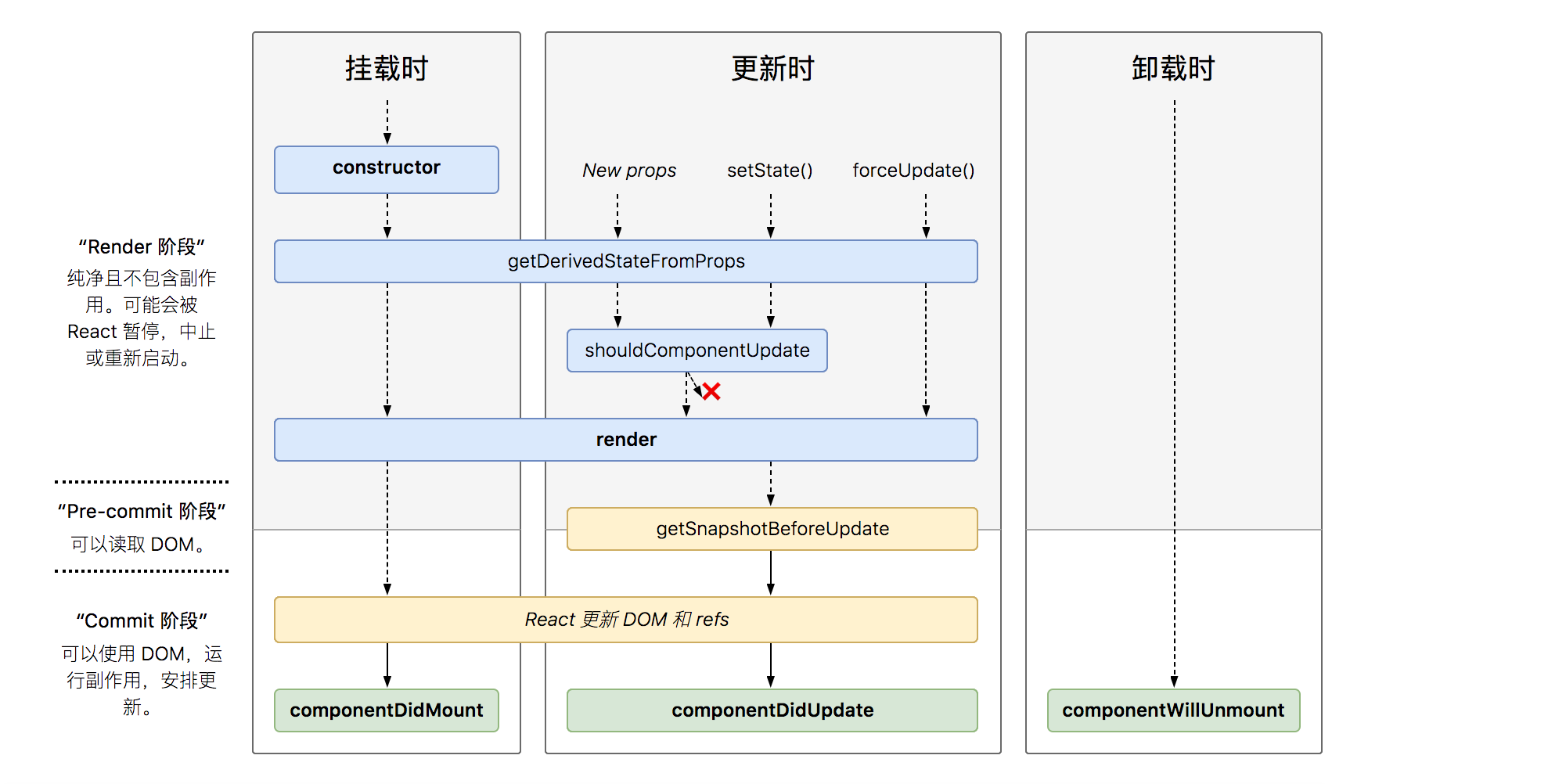
前端速通面经八股系列(八)—— React篇(上)
React目录 一、组件基础1. React 事件机制2. React的事件和普通的HTML事件有什么不同?3. React 组件中怎么做事件代理?它的原理是什么?4. React 高阶组件、Render props、hooks 有什么区别,为什么要不断迭代5. 对React-Fiber的理解…

Android13_SystemUI下拉框新增音量控制条
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Android13_SystemUI下拉框新增音量控制条 一、必备知识二、源码分析对比1.brightness模块分析对比2.statusbar/phone 对应模块对比对比初始化类声明对比构造方法 三、源码修改…

2024上海初中生古诗文大会备考:单选题真题和每道题独家解析
今天是2024年9月9日,距离2024年初中生古诗文大会初选的线上自由报名选拔已不足2个月了(官宣11月3日线上初选正式开赛)。许多孩子已经开始利用课余时间备赛了。 一、上海初中古诗文大会历年真题精选(参考答案和解析见文末)
*1. 下…
![数学建模笔记——TOPSIS[优劣解距离]法](https://img-blog.csdnimg.cn/img_convert/1d21edf66944b3ca39b4a238b9a0b9f9.png)
数学建模笔记——TOPSIS[优劣解距离]法
数学建模笔记——TOPSIS[优劣解距离法] TOPSIS(优劣解距离)法1. 基本概念2. 模型原理3. 基本步骤4. 典型例题4.1 矩阵正向化4.2 正向矩阵标准化4.3 计算得分并归一化4.4 python代码实现 TOPSIS(优劣解距离)法
1. 基本概念
C. L.Hwang和 K.Yoon于1981年首次提出 TOPSIS(Techni…

深兰科技董事长陈海波出席《中马建交五十周年高级别经贸合作》
2024年9月3日,中马建交50周年高级别经贸合作交流会暨马来西亚第九任首相VIP欢迎晚宴在北京隆重举行,深兰科技创始人、董事长陈海波先生应邀出席。 会议期间,双方举行了品牌出海合作签约仪式。在马来西亚首相雅各布先生的见证下,深…

代码随想录冲冲冲 Day40 动态规划Part8
121. 买卖股票的最佳时机
dp[i][0] 代表第i天持有股票手上的金额
dp[i][1] 代表第i天不持有股票手上的金额
初始化:
dp[0][0] 持有所以是-prices[0]
dp[0][1] 不持有所以是0;
递推公式:
dp[i][0] 既然是i天时持有,那么就是之前就持有&…

DeepSeek缓存命中技术,成本降低10倍
DeepSeek系列升级: DeepSeek发布最新的缓存命中技术,有效降低成本至0.1元/百万tokens,适用于文件读取和固定提示词。 点评:由于token消耗大部分是在系统提示词中,妥善使用确实可以极大降低成本,同时还能保证…

2024/9/9 数学“回头看”:
拐点的必要条件:
二阶导为0;
拐点与极值点什么关系?
一个点不可能既是拐点、又是极值点
穿针引线法:
设多项式的最高次项系数大于0,从数轴上最右边的根的右上方开始穿根,根据零点的重数的奇偶决定穿、不穿。