本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/441417.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

MySQL基础——DQL
DQL(Data Query Language,数据查询语言)是SQL中的一个子集,主要用于查询数据库中的数据。DQL的核心语句是 SELECT,它用于从一个或多个表中提取数据,并能够通过各种条件进行过滤、排序和聚合操作。下面是DQL…

9月12日星期四今日早报简报微语报早读
9月12日星期四,农历八月初十,早报微语早读。
1、今年第13号台风“贝碧嘉”已生成,未来趋向我国东海海面;
2、国台办:若台湾方面批准,金门“踩线团”有望十一假期前成行;
3、河北承德一矿企被…

音视频入门基础:WAV专题(9)——FFmpeg源码中计算WAV音频文件每个packet的duration和duration_time的实现
音视频入门基础:WAV专题系列文章:
音视频入门基础:WAV专题(1)——使用FFmpeg命令生成WAV音频文件
音视频入门基础:WAV专题(2)——WAV格式简介
音视频入门基础:WAV专题…

centos上开启mysql远程访问功能
自从mysql8以后,mysql有些命令变了,例如授权需要分成好几行。如果想远程访问mysql,那么可以这样做: mysql -u root -p mysql //先登录mysql
create user root% identified by 你自己的密码;//先建立一个root用户和密码
grant a…

OpenGL(四) 纹理贴图
几何模型&材质&纹理
渲染一个物体需要:
几何模型:决定了物体的形状材质:绝对了当灯光照到上面时的作用效果纹理:决定了物体的外观
纹理对象
纹理有2D的,有3D的。2D图像就是一张图片,3D图像是在…
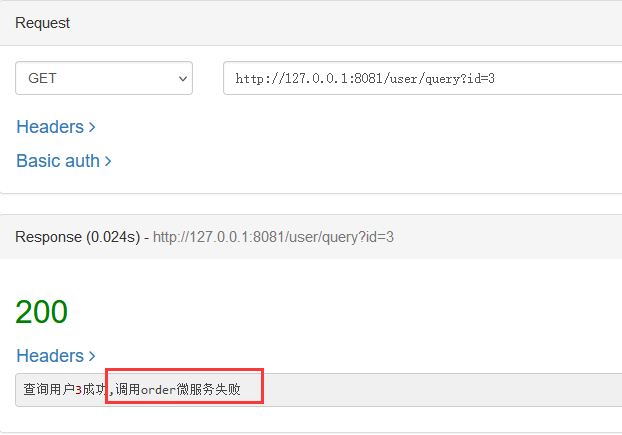
微服务保护学习笔记(四)FeignClient整合Sentinel、线程隔离(舱壁模式)、熔断降级
文章目录 前言3 隔离和降级3.1 FeignClient整合Sentinel3.1.1 搭建SpringCloud项目3.1.2 修改配置文件3.1.3 编写失败降级逻辑 3.2 线程隔离(舱壁模式)3.2.1 线程隔离的实现方式3.2.2 线程池隔离 3.3 熔断降级3.3.1 熔断降级的实现方式3.3.2 慢调用比例3…

PDB数据库数据查看和下载
RCSB(Research Collaboratory for Structural Bioinformatics)的PDB(Protein Data Bank)数据库是一个具有全球性影响力的科学数据库,主要用于存储和分享生物大分子(主要是蛋白质、核酸以及部分多糖…

干耳朵里面有坨屎出不来怎么办?口碑好的可视耳勺
干耳朵不比油耳朵,耳道中的耳屎过多会自己流到外耳道出来方便我们清理。干耳朵里面有坨屎出不来建议使用专业的工具来掏,在挖取过程中会更加精准和安全。但随着可视挖耳勺近几年越来越火爆,各种款式层出不穷,这其中也隐藏了不少劣…
![[数据集][目标检测]汽车头部尾部检测数据集VOC+YOLO格式5319张3类别](https://i-blog.csdnimg.cn/direct/338e6cc1459b4ad4bf63d486c8646032.png)
[数据集][目标检测]汽车头部尾部检测数据集VOC+YOLO格式5319张3类别
数据集制作单位:未来自主研究中心(FIRC) 版权单位:未来自主研究中心(FIRC) 版权声明:数据集仅仅供个人使用,不得在未授权情况下挂淘宝、咸鱼等交易网站公开售卖,由此引发的法律责任需自行承担 数据集格式:Pascal VOC格…

构建数字化时代的企业:数据驱动的信息架构战略
信息架构的黄金标准:全球企业转型的权威指南
The Open Group:信息架构领域的权威
全球范围的标准制定者
The Open Group是一家专注于企业架构和技术标准的全球性组织,拥有700多家成员机构,包括世界领先的科技公司、咨询公司和学…

中国书法—孙溟㠭篆刻《消失的心》
中国书法孙溟㠭篆刻作品《消失的心》 从小跟我多年的那颗单纯的心找不到了,那颗遇事激动砰砰跳的心没有了,身上多了一颗不属于我的世俗蒙尘铁打不跳动心,我已修成“正果”。甲辰秋月于寒舍小窗下溟㠭刊。 孙溟㠭篆刻《消失的心》 孙溟㠭…

Machine Learning: A Probabilistic Perspective 机器学习:概率视角 PDF免费分享
下载链接在博客最底部!!
之前需要参考这本书,但是大多数博客都是收费才能下载本书。
在网上找了好久才找到免费的资源,浪费了不少时间,在此分享以节约大家的时间。 链接: https://pan.baidu.com/s/1erFsMcVR0A_xT4fx…

C/C++ 网络编程之关于多核利用问题
在 C/C 网络编程之中,多核利用分为以下几类: 1、一个链接一个线程,即传统且淘汰的 MTA 架构 形式:每次捕获链接,create_new_thread 一个子线程出来处理。 优点:开发简单,维护简单。 缺点&#x…

如何通过食堂采购小程序端降低成本,提升效率?
随着数字化管理工具的普及,越来越多的食堂正在引入小程序来优化采购流程,减少成本和提升效率。食堂采购小程序端通过技术手段实现了自动化、智能化的管理方式,为管理者提供了极大的便利。本文将探讨如何利用技术手段开发一个高效的食堂采购小…

C#基础(11)函数重载
前言
前面我们已经完成了ref和out补充知识点的学习,以及函数参数相关的学习,今天便再次为函数补充一个知识点:函数重载。
函数重载是指在同一个作用域中,可以有多个同名函数,但参数列表不同。它的发展可以追溯到早期…

vue + Element UI table动态合并单元格
一、功能需求 1、根据名称相同的合并工作阶段和主要任务合并这两列,但主要任务内容一样,但要考虑主要任务一样,但工作阶段不一样的情况。(枞向合并) 2、落实情况里的定量内容和定性内容值一样则合并。(横向…

请解释JSP中的九大内置对象及其作用。什么是Java Web中的请求转发和重定向?它们有什么区别?
请解释JSP中的九大内置对象及其作用。
JSP(JavaServer Pages)中的九大内置对象(也称为隐式对象或自动对象)是JSP容器为每个页面提供的Java对象,这些对象在JSP页面被转换成Servlet时自动可用,无需显式声明。…

数学建模:控制预测类——时间序列ARIMA模型
目录
1.时间序列ARIMA模型
2.ARIMA模型大纲
3.模型详解
1)自回归模型AR(p)
2)移动平均模型MA(q)
3)自回归移动平均模型ARMA(p,q)
4)差分自回归移动平均模型ARIMA(p,d,q)
4.ARIMA模型建模步骤
5.建模步骤名词解释
1&…

解决:Vue 中 debugger 不生效
目录 1,问题2,解决2.1,修改 webpack 配置2.2,修改浏览器设置 1,问题
在 Vue 项目中,可以使用 debugger 在浏览器中开启调试。但有时却不生效。
2,解决
2.1,修改 webpack 配置
通…

onpm报错: Install failed
api 9 安装ohos/pulltorefresh2.0.1报错误 ohpm install ohos/pulltorefresh2.0.1
ohpm INFO: fetching meta info of package ohos/pulltorefresh
ohpm WARN: fetch meta info of package ohos/pulltorefresh failed - GET https://registry.npmjs.org/ohos/pulltorefresh 404…