本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/443322.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

C++数据结构-树的深度优先搜索及树形模拟法运用(进阶篇)
1. DFS简介
深度优先搜索算法(英语:Depth-First-Search,简称DFS)是一种用于遍历或搜索树或图的算法。 沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过或者在搜寻时结点不满足条件&am…

C/C++实现植物大战僵尸(PVZ)(打地鼠版)
🚀欢迎互三👉:程序猿方梓燚 💎💎 🚀关注博主,后期持续更新系列文章 🚀如果有错误感谢请大家批评指出,及时修改 🚀感谢大家点赞👍收藏⭐评论✍ 游戏…

探索Web3前沿:革新性算力共享平台,重塑数字资源利用新时代
基于Web3的算力共享平台
随着区块链技术的不断发展和Web3.0时代的到来,算力共享平台逐渐成为推动数字经济和人工智能发展的重要力量。基于Web3的算力共享平台通过去中心化、分布式网络等技术手段,实现了算力的高效、透明和安全的共享,为人工智能、科学研究、艺术创作等多个…
Maven 常见问题以及常用命令
常见问题 : 1. 识别不了maven项目 mvn clean install -Dmaven.test.skiptrue //构建
2. 打jar包时报异常
指定下jdk版本
常用命令:
mvn clean
mvn package
mvn install
mvn deploy

响应式网站的网站建设,需要注意什么?
响应式网站建设需要注意多个方面,以确保网站能够在各种设备和屏幕尺寸上提供一致且良好的用户体验。下面详细介绍响应式网站建设的注意事项:
响应式网站的网站建设,需要注意什么?
考虑多终端适配 设计样式:在设计响应式网站时&…

C++进阶:二叉搜索树
✨✨所属专栏:C✨✨ ✨✨作者主页:嶔某✨✨ ⼆叉搜索树的概念
⼆叉搜索树⼜称⼆叉排序树,它或者是⼀棵空树,或者是具有以下性质的⼆叉树: • 若它的左⼦树不为空,则左⼦树上所有结点的值都⼩于等于根结点的值 • 若…
ffmpeg实现视频的合成与分割
视频合成与分割程序使用 作者开发了一款软件,可以实现对视频的合成和分割,界面如下: 播放时,可以选择多个视频源;在选中“保存视频”情况下,会将多个视频源合成一个视频。如果只取一个视频源中一段视频…
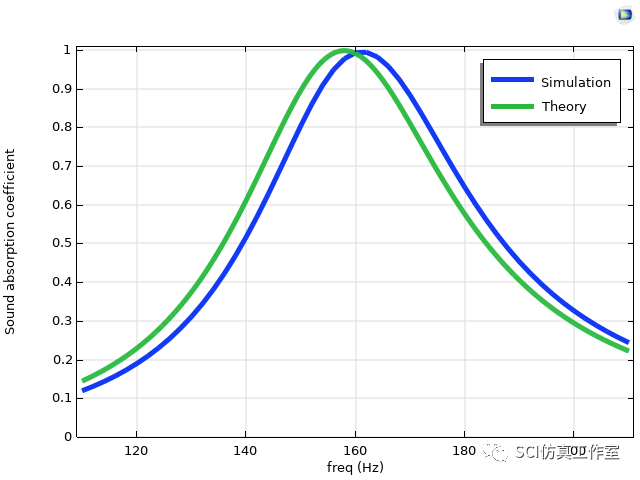
Comsol 利用多孔材料填充复合吸声器,拓宽低频完美吸声
参考文献:Cheng B , Gao N , Huang Y ,et al.Broadening perfect sound absorption by composite absorber filled with porous material at low frequency:[J].Journal of Vibration and Control, 2022, 28(3-4):410-424.DOI:10.1177/1077546320980214.
为了提高低…

【C++前后缀分解 动态规划】2100. 适合野炊的日子|1702
本文涉及知道点
C前后缀分解 C动态规划
LeetCode2100. 适合野炊的日子
你和朋友们准备去野炊。给你一个下标从 0 开始的整数数组 security ,其中 security[i] 是第 i 天的建议出行指数。日子从 0 开始编号。同时给你一个整数 time 。 如果第 i 天满足以下所有条件…

今天中秋,中秋快乐,分析一个中秋月饼的项目
特色功能 使用obj模型,搭配tga文件,附加上颜色 normalMap 是让字和线条看起来更清楚和真实 高光贴图 凹凸贴图 ......
源码
https://github.com/Lonely1201/lonely1201.github.io/tree/main/Juejin/mooncake
在线预览
https://lonely1201.githu…

.net core 通过Sqlsugar生成实体
通过替换字符串的方式生成代码,其他代码也可以通这种方式生成 直接上代码
设置模板 将这几个模板文件设置为:嵌入资源 模板内容:
using SqlSugar;namespace {Namespace}.Domain.Admin.{ModelName};
/// <summary>
/// {TableDisplay…

“钧瓷联合体”激活禹州经济发展新引擎
大禹智库
第 105期(总第436期) 2024-9-16 钧瓷联合体对禹州经济发展的作用是多方面的,主要体现在以下几个方面: 一、促进钧瓷产业集聚与升级
钧瓷联合体的成立有助于促进钧瓷产业的集聚效应,形成产业集群。通过整合行…
rocky Linux 9.4系统配置zabbix监控MySQL主从复制状态与配置钉钉告警
MySQL主从复制原理:
1. 主从复制的基本概念 主服务器(Master):负责处理所有的写操作(INSERT、UPDATE、DELETE),并将这些操作记录到二进制日志(binary log)中。 从服务器…
小程序开发设计-第一个小程序:创建小程序项目④
上一篇文章导航:
小程序开发设计-第一个小程序:安装开发者工具③-CSDN博客https://blog.csdn.net/qq_60872637/article/details/142219152?spm1001.2014.3001.5501
须知:注:不同版本选项有所不同,并无大碍。 一、创…

EndnoteX9安装及使用教程
EndnoteX9安装及使用教程
一、EndNote安装
1.1 下载
这里提供一个下载链接: 链接:https://pan.baidu.com/s/1RlGJksQ67YDIhz4tBmph6Q 提取码:5210 解压完成后,如下所示:
1.2 安装
双击右键进行安装 安装比较简单…

Python酷库之旅-第三方库Pandas(119)
目录
一、用法精讲
526、pandas.DataFrame.head方法
526-1、语法
526-2、参数
526-3、功能
526-4、返回值
526-5、说明
526-6、用法
526-6-1、数据准备
526-6-2、代码示例
526-6-3、结果输出
527、pandas.DataFrame.idxmax方法
527-1、语法
527-2、参数
527-3、…

MySQL之表内容的增删改查
目录
一:Create
二:Retrieve
1.select列 2.where条件
3.结果排序
4. 筛选分页结果
三:Update
四:Delete
1.删除数据
2. 截断表
五:插入查询结果
六:聚合函数
七:group by子句的使用 表内容的CRUD操作 : Create(创建), Retrieve(读取)…

arcgisPro地理配准
1、添加图像 2、在【影像】选项卡中,点击【地理配准】 3、 点击添加控制点 4、选择影像左上角格点,然后右击填入目标点的投影坐标 5、依次输入四个格角点的坐标 6、点击【变换】按钮,选择【一阶多项式(仿射)】变换 7…

Objects as Points基于中心点的目标检测方法CenterNet—CVPR2019
Anchor Free目标检测算法—CenterNet
Objects as Points论文解析 Anchor Free和Anchor Base方法的区别在于是否在检测的过程中生成大量的先验框。CenterNet直接预测物体的中心点的位置坐标。 CenterNet本质上类似于一种关键点的识别。识别的是物体的中心点位置。 有了中心点之…

Zookeeper学习
文章目录 学习第 1 章 Zookeeper 入门1.1 概述Zookeeper工作机制 1.2 特点1.3 数据结构1.4 应用场景统一命名服务统一配置管理统一集群管理服务器动态上下线软负载均衡 1.5 下载zookeeper 第 2 章 Zookeeper 本地安装2.1 本地模式安装安装前准备配置修改操作 Zookeeper本地安装…