本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/443382.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

信息安全数学基础(7)最小公倍数
前言 在信息安全数学基础中,最小公倍数(Least Common Multiple, LCM)是一个重要的概念,它经常与最大公约数(Greatest Common Divisor, GCD)一起出现,两者在数论、密码学、模运算等领域都有广泛的…

手把手教你:在微信小程序中加载map并实现拖拽添加标记定位
本文将为大家详细介绍如何在微信小程序中加载map组件,并实现拖拽标记定位功能。
实现步骤
1、首先,我们需要在项目的app.json文件中添加map组件的相关配置。如下所示:
{"pages": ["pages/index/index"],"permiss…

CesiumJS+SuperMap3D.js混用实现可视域分析 S3M图层加载 裁剪区域绘制
版本简介:
cesium:1.99;Supermap3D:SuperMap iClient JavaScript 11i(2023);
官方下载文档链家:SuperMap技术资源中心|为您提供全面的在线技术服务
示例参考:support.supermap.com.cn:8090/w…
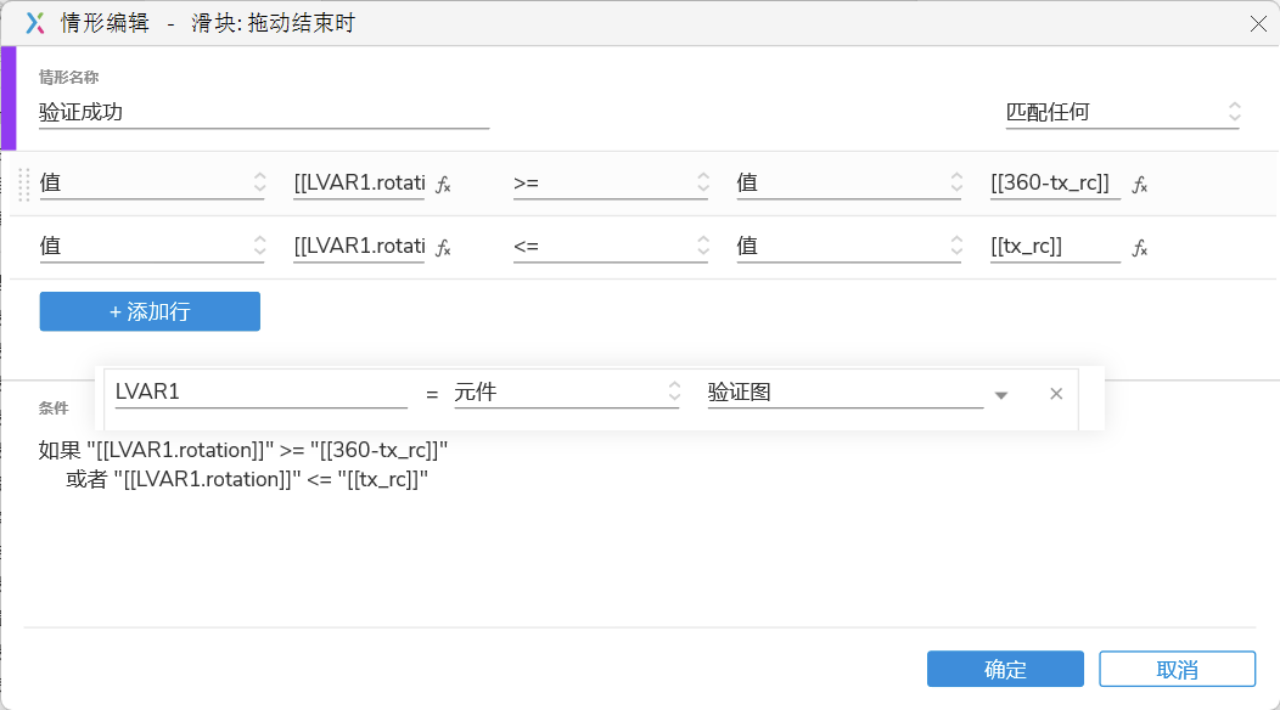
Axure RP实战:打造高效图形旋转验证码
Axure RP实战:打造高效图形旋转验证码
在数字产品设计的海洋中,验证码环节往往是用户交互体验的细微之处,却承载着验证用户身份的重要任务。
传统的文本验证码虽然简单直接,但随着用户需求的提高和设计趋势的发展,它…

智慧火灾应急救援:无人机、直升机航拍视角下的火灾应急救援检测数据集代码
智慧火灾应急救援:无人机、直升机航拍视角下的火灾应急救援检测数据集
引言
随着科技的发展,无人机、直升机等飞行器在火灾应急救援中的应用越来越广泛。这些飞行器不仅能快速到达火场,而且可以通过搭载的高清摄像机和其他传感器获取火场的…

DFS:深搜+回溯+剪枝实战解决OJ问题
✨✨✨学习的道路很枯燥,希望我们能并肩走下来! 文章目录 目录
文章目录
前言
一 排列、子集问题
1.1 全排列I
1.2 子集I 1.3 找出所有子集的异或总和
1.4 全排列II
1.5 字母大小写全排列
1.6 优美的排列
二 组合问题
2.1 电话号码的数字组合 …

linux驱动开发-arm汇编基础
目录
写在前面
1、Cortex-A7 处理器有 9 种处理模式
2、Cortex-A 寄存器组
通用寄存器
1、汇编语法
2、Cortex-A7 常用汇编指令
2.1 处理器内部数据传输指令
2.1.1 传输数据操作类型
1、MOV指令
2、MRS指令
3、MSR指令
2.2、存储器访问指令
2.2.1 LDR指令
2.2.2 …

电气自动化入门02:三相交流电及其主要应用参数
视频链接:1.2 电工知识:三相交流电及其主要应用参数_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1PJ41117PW?p3&vd_sourceb5775c3a4ea16a5306db9c7c1c1486b5
1.什么是交流电
交流电就是:大小和方向都随时间不断变化的电流
2…

人工智能时代,程序员如何保持核心竞争力?
随着AIGC(如ChatGPT、MidJourney、Claude等)大语言模型的快速发展,程序员的工作模式正经历前所未有的变革。虽然AI辅助编程工具的普及为程序员提供了更高的工作效率,但也引发了对未来工作的深刻思考。面对这一趋势,程序…

Idea 中的一些配置
配置 javap
jdk 自带的 javap 可以用来查看字节码信息。
配置过程:
打开设置,定位到 Tools,External Tools新建项,Program 中填 javap 的路径Argument 中填 -c $FileClass$Working directory 中填 $OutputPath$
Argument 中也…

计算机三级网络技术总结(三)
宽带(bandwidth)单位是kbpspos framing sdh / pos framing sonetpos flag s1s0 2 / pos flag s1s0 0CRC 32network <目的网络的ip地址><子网掩码的反码>area 0area 0 range<子网地址><子网掩码>ip route <目的网络地址>&l…

前端 + 接口请求实现 vue 动态路由
前端 接口请求实现 vue 动态路由
在 Vue 应用中,通过前端结合后端接口请求来实现动态路由是一种常见且有效的权限控制方案。这种方法允许前端根据用户的角色和权限,动态生成和加载路由,而不是在应用启动时就固定所有的路由配置。
实现原理…

2024.9.16 day 1 pytorch安装及环境配置
一、配置pytorch环境,安装pytorch
1.查看python版本
python --version
2.在anaconda命令中创建pytorch环境
conda create -n pytorch python3.12(python版本)
3.pytorch安装
pytorch首页
PyTorchhttps://pytorch.org/
os为windows推荐package选择…

【Java数据结构】二叉树
目录 树树的特征树的概念 二叉树两种特殊的二叉树二叉树的性质二叉树的基本操作4 种遍历二叉树的方式判断一棵树是不是完全二叉树获取二叉树总共的节点个数获取叶子节点的个数获取第 k 层的节点个数获取二叉树的高度检测值为 value 的元素是否存在 二叉树基本操作完整代码 树
…

【机器学习】--- 自监督学习
1. 引言
机器学习近年来的发展迅猛,许多领域都在不断产生新的突破。在监督学习和无监督学习之外,自监督学习(Self-Supervised Learning, SSL)作为一种新兴的学习范式,逐渐成为机器学习研究的热门话题之一。自监督学习…

Vite - 依赖预购建
目录 1,目的1.1,CommonJS 和 UMD 模块的兼容性1.2,性能 2,作用范围和配置2.1,作用范围2.2,自定义配置 4,缓存实现过程5,注意点 官方文档
1,目的
主要是下面2点…

Expectation disarray Analysts’ growth forecast anomaly in China
Expectation disarray: Analysts’ growth forecast anomaly in China 论文阅读 文章目录 Expectation disarray: Analysts’ growth forecast anomaly in China 论文阅读 Abstract中美市场的差异如何调和中美市场的相似性和差异为什么美国分析师预测导致负向收益 MethodologyD…

2、vectorCast集成测试常用功能
一、什么是软件集成测试
软件集成测试主要来源于A-SPICE和ISO26262这两个汽车行业内的标准规范。
用途与范围
纯软件模块的功能测试,不涉及和硬件相关的功能测试
模块/组件内部的功能测试(module/component test)
模块与模块之间的接口测试
模块/组件的划分需参考softwa…

1.使用 IDEA 过程中的英语积累 - File 菜单(每一次重点积累 5 个单词)
前言
学习可以不局限于传统的书籍和课堂,各种生活的元素也都可以做为我们的学习对象,本文将利用 IDEA 页面上的各种英文元素来做英语的积累,如此做有 3 大利 这些软件在我们工作中是时时刻刻接触的,借此做英语积累再合适不过&…

MATLAB系列03:分支语句和编程设计
MATLAB系列03:分支语句和编程设计 3. 分支语句和编程设计3.1 自上而下的编程方法简介3.2 伪代码的应用3.3 关系运算符和逻辑运算符3.3.1 关系运算符3.3.2 小心和~运算符3.3.3 逻辑运算符3.3.4 逻辑函数 3.4 选择结构3.4.1 if结构3.4.2 switch结构3.4.3 try/catch结构…