本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/443512.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

动态规划:07.路径问题_珠宝的最大价值_C++
题目链接:LCR 166. 珠宝的最高价值 - 力扣(LeetCode)https://leetcode.cn/problems/li-wu-de-zui-da-jie-zhi-lcof/description/
一、题目解析
题目: 解析:
有过做前几道题的经验,我们会发现这道题其实就…
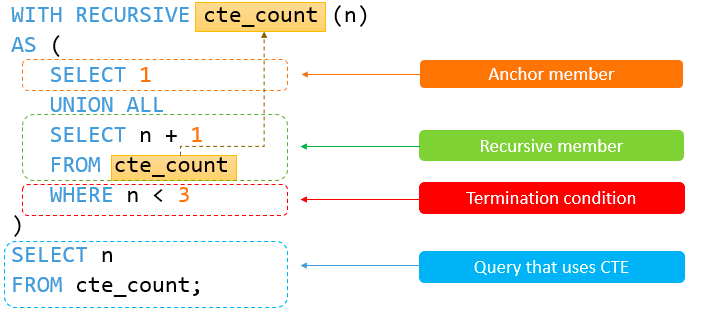
MySQL篇(窗口函数/公用表达式(CTE))
目录 讲解一:窗口函数
一、简介
二、常见操作
1. sumgroup by常规的聚合函数操作
2. sum窗口函数的聚合操作
三、基本语法
1. Function(arg1,..., argn)
1.1. 聚合函数
sum函数:求和
min函数 :最小值
1.2. 排序函数
1.3. 跨行函数…

markdown 使用技巧
文章目录 markdown使用技巧1.标题快捷键设置2.文档可读性设置 markdown使用技巧
1.标题快捷键设置
ctl 1:一级标题
ctl 2:二级标题
ctl 3:三级标题
ctl 4:四级标题
...2.文档可读性设置 输入~~~pro 可选择代码框,并且可以选择不同的字体 ctrl shift ] : 可…

基于MicroPython的ESP32控制LED灯闪烁设计方案的Wokwi仿真
以下是一个基于MicroPython的ESP32控制LED灯闪烁设计方案的Wokwi仿真:
一、硬件准备: 在Wokwi仿真平台(https://wokwi.com/)选择ESP32开发板,添加一个LED灯,和一个220欧姆限流电阻。
二、硬件连接:
1. 将LED灯的阳极…

gin配置swagger文档
一、基本准备工作 1、安装依赖包 go get -u github.com/swaggo/swag/cmd/swag
go get -u github.com/swaggo/gin-swagger
go get -u github.com/swaggo/files2、在根目录上配置swagger的路由文件 //2.初始化路由router : initialize.Routers()// 配置swaggerdocs.SwaggerInfo…

Linux进程等待 | 程序替换
进程终止
一个进程退出了,无非只有三种情况:
代码跑完了,结果正确代码跑完了,结果不正确代码没跑完,程序异常退出了
代码跑完了,我们可以通过退出码获取其结果是否正确,(这个退出…


【OJ刷题】双指针问题6
这里是阿川的博客,祝您变得更强 ✨ 个人主页:在线OJ的阿川 💖文章专栏:OJ刷题入门到进阶 🌏代码仓库: 写在开头
现在您看到的是我的结论或想法,但在这背后凝结了大量的思考、经验和讨论 目录 1…

Rust使用Actix-web和SeaORM库开发WebAPI通过Swagger UI查看接口文档
本文将介绍Rust语言使用Actix-web和SeaORM库,数据库使用PostgreSQL,开发增删改查项目,同时可以通过Swagger UI查看接口文档和查看标准Rust文档
开始项目
首先创建新项目,名称为rusty_crab_api
cargo new rusty_crab_apiCargo.t…

中标喜讯!湖北产教融合教育研究院携手湖北医药学院,共筑同等学力申硕新篇章
在深化教育改革、推动产教融合的大潮中,湖北产教融合教育研究院再传捷报!其控股子公司——武汉产教融汇教育科技有限公司,凭借卓越的技术研发实力、丰富的教育资源储备及高效的运营管理能力,成功中标湖北医药学院同等学力申硕工作…

Windows下SDL2创建最简单的一个窗口
先看运行效果 再上代码: #include <stdio.h>
#include "SDL.h"int main(int argc, char* argv[])
{// 初始化SDL视频子系统if (SDL_Init(SDL_INIT_VIDEO) -1){printf("Error: %s\n", SDL_GetError());return -1;} // 创建一个窗口SDL_…

通过防火墙分段增强网络安全
什么是网络分段
随着组织规模的扩大,管理一个不断扩大的网络成为一件棘手的事情,同时确保安全性、合规性、性能和不间断的运行可能是一项艰巨的任务。为了克服这一挑战,网络管理员部署了网络分段,这是一种将网络划分为更小且易…

nvm无法下载npm的问题
1、问题
执行 nvm install 14.21.3 命令,node可以正常下载成功,npm下载失败
2、nvm配置信息
…/nvm/settings.txt
root: D:\soft\nvm
path: D:\soft\nodejs
node_mirror: npmmirror.com/mirrors/node/
npm_mirror: registry.npmmirror.com/mirrors/…


论文阅读: SigLit | SigLip |Sigmoid Loss for Language Image Pre-Training
论文地址:https://arxiv.org/pdf/2303.15343 项目地址:https://github.com/google-research/big_vision 发表时间:2023年3月27日 我们提出了一种用于语言图像预训练(SigLIP)的简单成对 Sigmoid 损失。与使用 softmax …

避免服务器安装多个mysql引起冲突的安装方法
最近工作中涉及到了数据迁移的工作. 需要升级mysql版本到8.4.2为了避免升级后服务出现异常, 因此需要保留原来的mysql,所以会出现一台服务器上运行两个mysql的情况
mysql并不陌生, 但是安装不当很容易引起服务配置文件的冲突,导致服务不可用, 今天就来介绍一种可以完美避免冲突…

linux网络编程1
24.9.16学习目录 一.TCP/IP协议简介1.TCP/IP的分层结构2.协议的简介 二、MAC地址和IP地址1.网卡2.MAC地址3.IP地址(1)IP地址的分类(2)IP地址的特点(3)回环IP地址 3.子网掩码4.端口(1)…

7天速成前端 ------学习日志 (继苍穹外卖之后)
前端速成计划总结: 全26h课程,包含html,css,js,vue3,预计7天内学完。
起始日期:9.16 预计截止:9.22 每日更新,学完为止。 学前计划 课…

Linux操作系统入门(五)
—————————————————————————————————————————
至此,大部分Linux操作系统的文件操作指令已经总结完成,最后还需进行vim编辑器的使用
使用方法:在FinalShell终端中输入"vim [文件]",以下图…

【CPP】模板(后篇)
目录 13.1 非类型模板参数13.2 函数模板的特化13.3 类模板的特化13.4 模板的分离编译 这里是oldking呐呐,感谢阅读口牙!先赞后看,养成习惯! 个人主页:oldking呐呐 专栏主页:深入CPP语法口牙 13.1 非类型模板参数
顾名思义,非类型模板参数就是一个模板的参数,只不过不是类型,而…