本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/125926.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
基于微信小程序的小区服务管理系统设计与实现(源码+lw+部署文档+讲解等)
前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 👇🏻…


(10)(10.9) 术语表(三)
文章目录
1 Oilpan
2 OSD
3 PCB
4 PCM
5 PDB
6 PIC
7 PID
8 POI
9 PPM
10 PWM
11 PX4FMU/PX4IO
12 RTL
13 SiRF III
14 Sketch
15 SVN
16 Telemetry System
17 Thermopile
18 UAV
19 VLOS
20 WAAS
21 Xbee
22 ZigBee 1 Oilpan
Oilpan:这是一…

Python实战:用多线程和多进程打造高效爬虫
文章目录 🍋引言🍋为什么要使用多线程和多进程?🍋线程的常用方法🍋线程锁(也称为互斥锁或简称锁)🍋小案例🍋实战---手办网🍋总结 🍋引言 在网络爬…
MySQL的时间差函数、日期转换计算函数
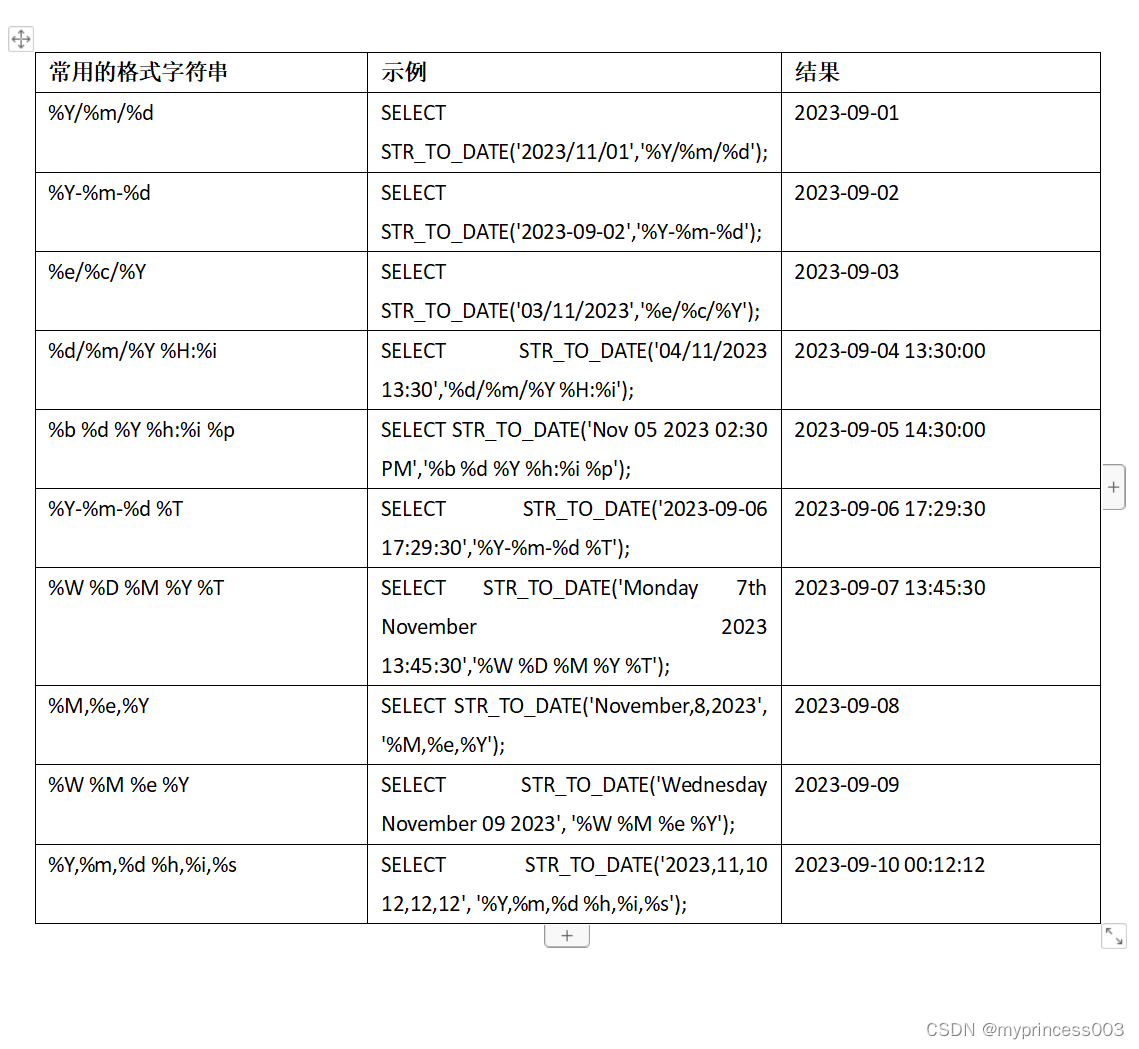
MySQL的时间差函数(TIMESTAMPDIFF、DATEDIFF)、日期转换计算函数(date_add、day、date_format、str_to_date)
时间差函数(TIMESTAMPDIFF、DATEDIFF)
需要用MySQL计算时间差,使用TIMESTAMPDIFF、DATEDIFF,记录一下实验结果
--0
…

大模型训练之加速篇 -attention优化【MQA-> flashAttention】
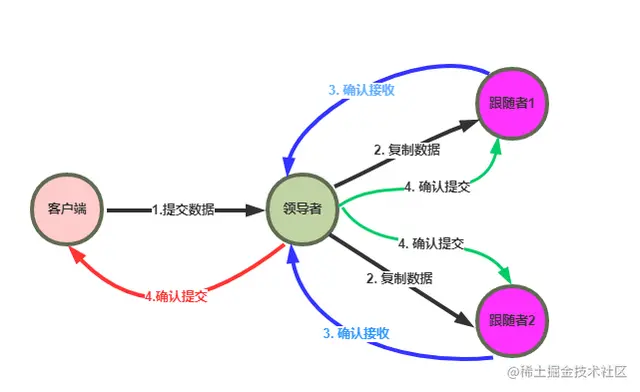
MQA (multi query attention)
Fast Transformer Decoding: One Write-Head is All You Need MQA 是 19 年提出的一种新的 Attention 机制,其能够在保证模型效果的同时加快 decoder 生成 token 的速度。 那到底能提升多少的速度呢,我们来看论文中给出的结…


OpenCV(三十八):二维码检测
1.二维码识别原理
功能图形: 位置探测图形:通常,二维码中有三个位置探测图形,呈现L型或大角度十字架形状,分布在二维码的三个角上,用于帮助扫描设备定位二维码的位置和方向。 位置探测图形分隔符…

PoE交换机出现不稳定的原因有哪些?
带有供电设备的PoE交换机给使用者带来了方便,因此被广泛应用。然而,很多使用商反映他们所使用的PoE交换机不稳定。那么,PoE交换机出现不稳定的原因有哪些? 首先需要考虑的是数据传输的距离。尽管PoE供电交换机具有方便灵活的特点&…

leetcode646. 最长数对链(java)
最长数对链 题目描述贪心解法二 动态规划 dp 题目描述 难度 - 中等 leetcode646. 最长数对链(java) 给你一个由 n 个数对组成的数对数组 pairs ,其中 pairs[i] [lefti, righti] 且 lefti < righti 。 现在,我们定义一种 跟随 关系,当且仅…
使用扩展运算符(...)合并数组
在项目开发过程中,有一个需求,需要制作一个带有标题的表格,如下所示: 和后端开发沟通时,后端计划返回三个数组,标题写死。所以我需要做的就是把数组合并,然后在三个数组之前增加标题。这里我采用…
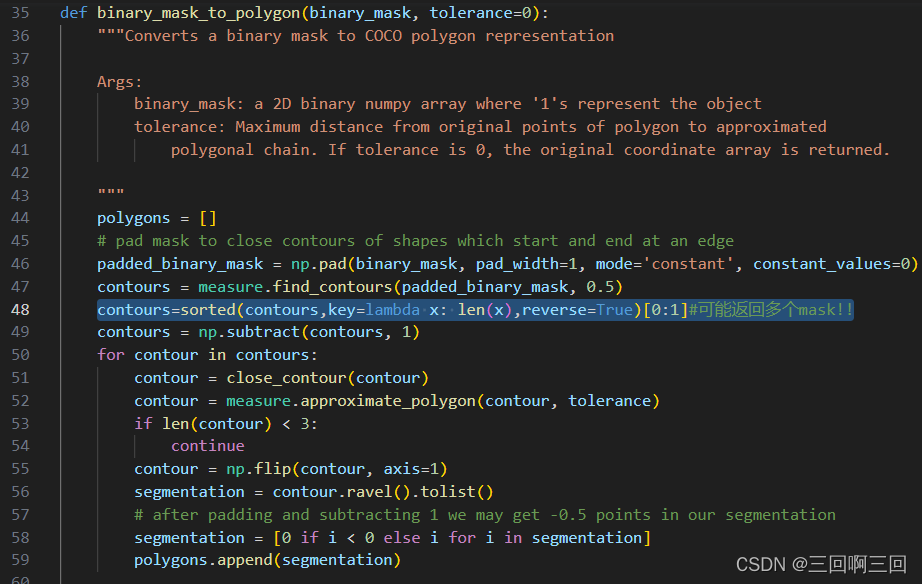
解决pycococreatortools安装问题
我的环境:
python:3.8.18
numpy:1.24.4
问题一:
用git文档的方法下载失败:
pip install gitgit://github.com/waspinator/coco.git2.1.0 解决:
用这行 pip install githttps://github.com/waspinator/pycococreator.git 问题…

DBAPI插件开发指南
DBAPI插件开发指南
插件市场
您可以去插件市场下载插件
插件的作用
DBAPI的插件分4类,分别是数据转换插件、缓存插件、告警插件、全局数据转化插件
缓存插件
对执行器结果进行缓存,比如SQL执行器,对查询类SQL,sql查询结果进…
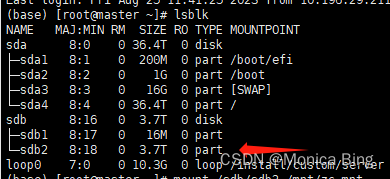
linux挂载ntfs格式硬盘
先把硬盘连接到服务器上 如果没有安装ntfs-3g软件的话 sudo apt-get install ntfs-3g查看ntfs分区并找到要挂载的NTFS分区的设备名 lsblk这里我是根据SIZE找到的设备名 也可以挂载之前先查看一下,挂载之后再看新增了哪个分区,就可以定位到啦 开始mnt 先…
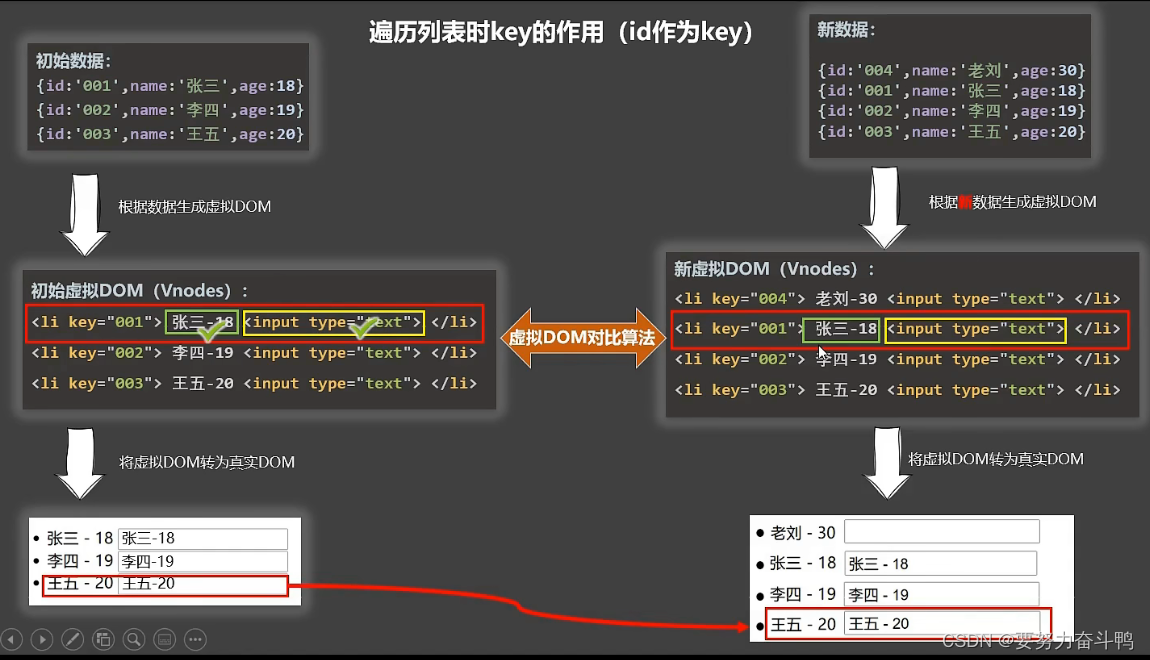
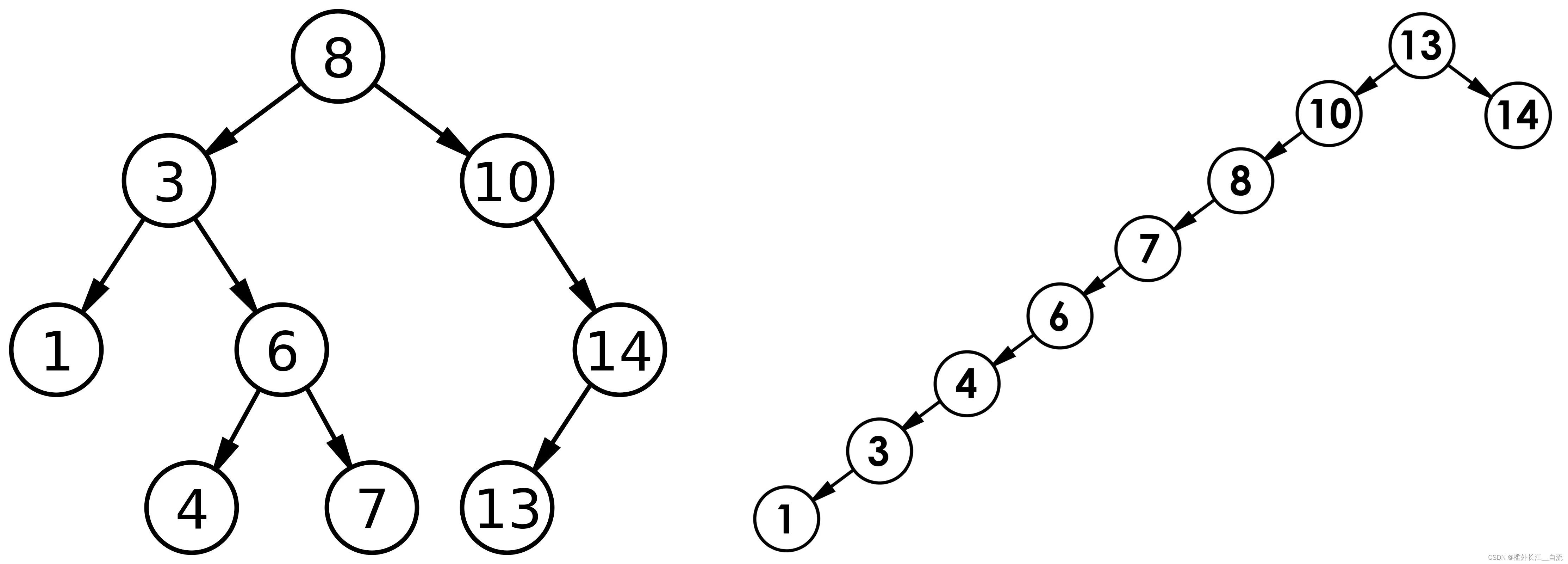
二叉搜索树(BST,Binary Search Tree)
文章目录 1. 二叉搜索树1.1 二叉搜索树概念1.2 二叉搜索树的查找1.3 二叉搜索树的插入1.4 二叉搜索树的删除 2 二叉搜索树的实现3 二叉搜索树的应用3.1二叉搜索树的性能分析 1. 二叉搜索树
1.1 二叉搜索树概念
二叉搜索树又称二叉排序树,它或者是一棵空树…

python处理CSV文件
CSV库还有其他处理CSV的方法,这里只是介绍几个常用的,后面如果用到别的会进行更新
目录
1 生成一个新的csv文件,并向其中写一点东西
2 单纯往里面写几行 3 读取csv文件 1 生成一个新的csv文件,并向其中写一点东西
import…
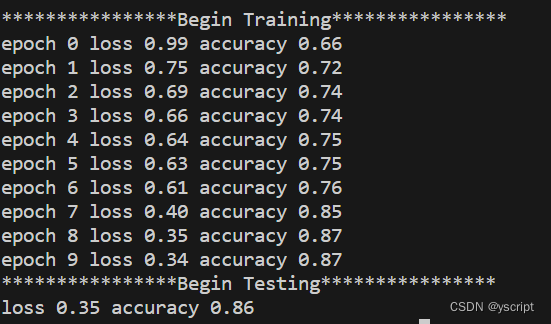
Pytorch-MLP-Mnist
文章目录 model.pymain.py参数设置注意事项初始化权重如果发现loss和acc不变关于数据下载关于输出格式 运行图 model.py
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.init as initclass MLP_cls(nn.Module):def __init__(self,in_dim28*28):super…

Java实现添加文字水印、图片水印功能实战
Java实现添加文字水印、图片水印功能实战
本文介绍java实现在图片上加文字水印的方法,水印可以是图片或者文字,操作方便。
java实现给图片添加水印实现步骤:
获取原图片对象信息(本地图片或网络图片)添加水印&#…