本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/438562.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

Vue学习:v-model绑定文本框、单选按钮、下拉菜单、复选框等
v-model指令可以在组件上使用以实现双向绑定,之前学习过v-model绑定文本框和下拉菜单,今天把表单的几个控件单选按钮radio、复选框checkbox、多行文本框textarea都试着绑定了一下。
一、单行文本框和多行文本框
<p>1.单行文本框</p>
用户名…
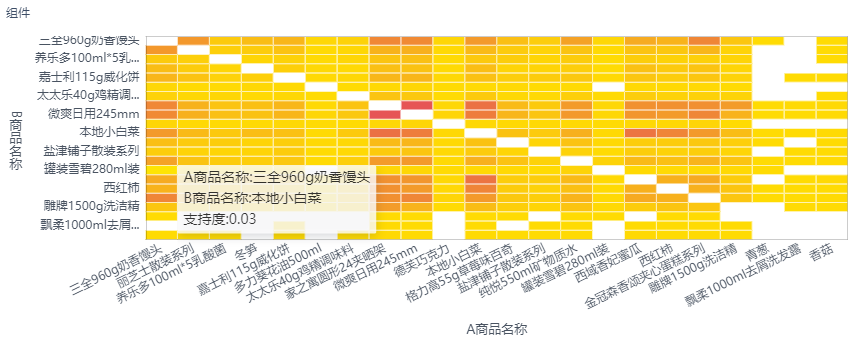
真实案例分享:零售企业如何避免销售数据的无效分析?
在零售业务的数据分析中,无效分析不仅浪费时间和资源,还可能导致错误的决策。为了避免这种情况,企业必须采取策略来确保他们的数据分析工作能够产生实际的商业价值。本文将通过行业内真实的案例,探讨零售企业如何通过精心设计的数…

【C语言进阶】C语言进阶教程:利用结构体、联合体和枚举自定义数据类型
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C语言 “ 登神长阶 ” 🤡往期回顾🤡:C语言内存管理函数 🌹🌹期待您的关注 🌹🌹 ❀C语言自定义类型 &#…

运维领域的先进思想和趋势
在运维领域,除了“基础设施即代码(IaC)”之外,还有许多先进的思想和方法正在推动运维的进步。以下是一些关键的理念和趋势: 智能运维(AIOps):利用人工智能和机器学习技术来自动化和优…
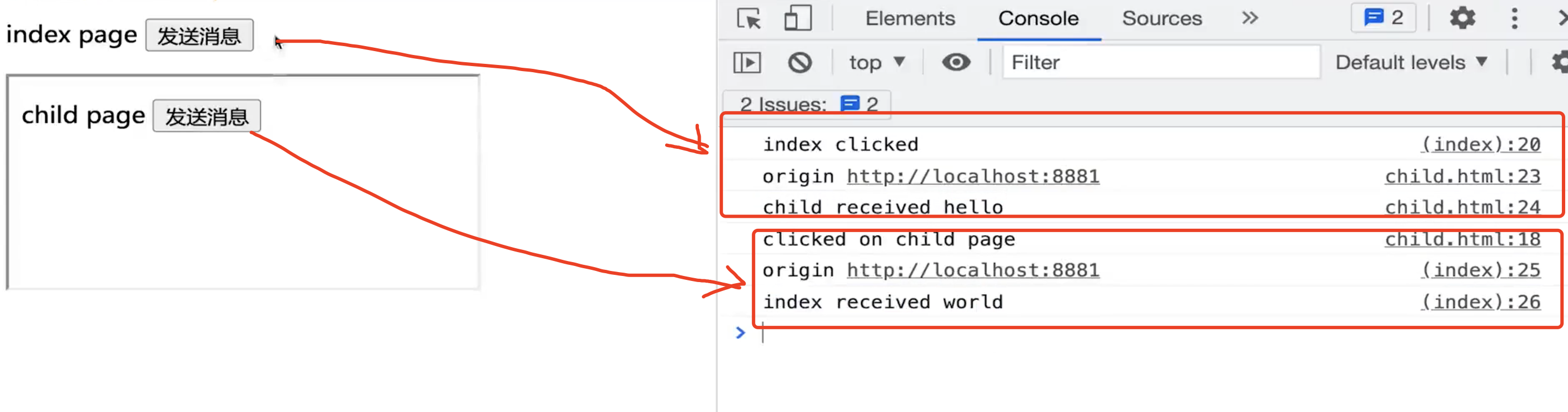
如何实现网页多标签tab通讯?
通过websocket 无跨域限制需要服务端支持,成本高通过localStorage同域通讯(推荐) 同域的A和B两个页面A页面设置localStorageB页面可监听到localStorage值的修改通过SharedWorker通讯 SharedWorker是WebWorker的一种WebWorker可开启子进程执行…

JavaWeb - Maven
Maven
apache旗下的一个来源项目,一款用于管理和构建java项目的工具,它基于项目对象模型(POM)的概念,通过一小段描述信息来管理项目的构建。
作用 安装
解压官网下载的压缩包
配置本地仓库,修改conf/se…

机器学习(西瓜书)第 3 章 线性模型
3.1 基本形式
线性模型要做的有两类任务:分类任务、回归任务
分类的核心就是求出一条直线w的参数,使得直线上方和直线下方分别属于两类不同的样本
回归就是用来拟合尽可能多的点的分布的方法,我们可以通过拟合的直线知道一个新样本的相关数…
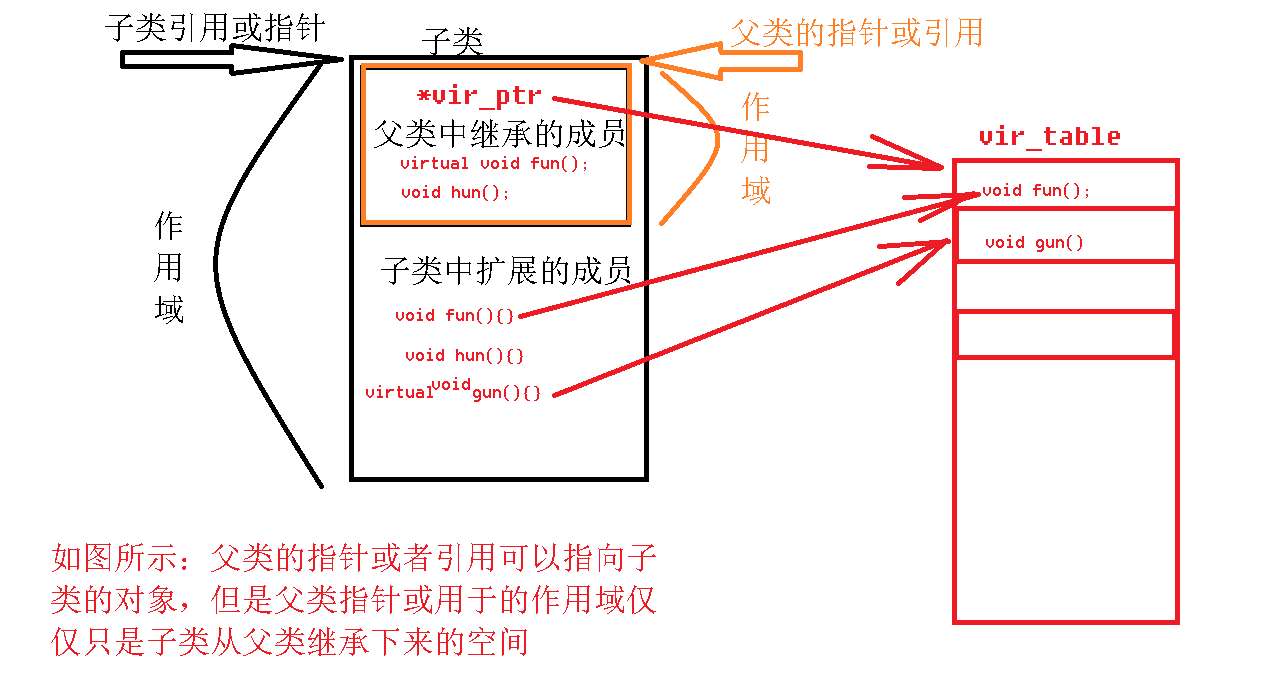
day47——面向对象特征之继承
一、继承(inhert)
面向对象三大特征:封装、继承、多态
继承:所谓继承,是类与类之间的关系。就是基于一个已有的类,来创建出一个新类的过程叫做继承。主要提高代码的复用性。
1.1 继承的作用
1> 实现…

Windows conda常用方法
这里写目录标题 conda链接jupyter conda链接jupyter
列出当前所有环境: conda env list 创建新环境: conda create -n your_env_name pythonX.X(2.7、3.6、3.8等) 激活环境: conda activate your_env_name 链接jupyte…

VXLAN 为何采用UDP
VXLAN 简介
VXLAN是一种网络虚拟化技术,它通过在UDP数据包中封装MAC地址和IP信息,使得二层网络(如以太网)能够跨越三层网络(如IP网络)进行扩展。这种封装方式不仅支持TCP流量的传输,还能有效处…

SpringCloud开发实战(四):Feign远程调用
目录 SpringCloud开发实战(一):搭建SpringCloud框架 SpringCloud开发实战(二):通过RestTemplate实现远程调用 SpringCloud开发实战(三):集成Eureka注册中心 Feign简介
我…

机器学习(五) -- 监督学习(8) --神经网络1
机器学习系列文章目录及序言深度学习系列文章目录及序言
上篇:机器学习(五) -- 无监督学习(2) --降维2 下篇:机器学习(五) -- 监督学习(8) --神经网络2 前言…

基于SSM+MySQL的医院在线挂号系统
系统背景 在当前数字化转型浪潮的推动下,医疗服务行业正经历着前所未有的变革。随着人口老龄化的加剧、患者就医需求的日益增长以及医疗资源分布不均等问题的凸显,传统的就医模式已难以满足患者对于便捷、高效医疗服务的需求。因此,构建一套基…

设计模式 —— 单例模式
文章目录 一、单例模式1.1 单例模式定义1.2 单例模式的优点1.3 单例模式的缺点1.4 单例模式的使用场景 二、普通案例2.1 饿汉式单例模式(Eager Initialization Singleton)2.2 懒汉式单例模式(Lazy Initialization Singleton) 参考资料 本文源代码地址为 java-demos/singeleton-…

探索未来科技发展:芯片设计的创新之路
在当今这个日新月异的数字时代,芯片设计作为信息技术的核心驱动力,正以前所未有的速度推动着社会进步与产业升级。作为科技领域的璀璨明珠,芯片设计不仅关乎数据处理的速度与效率,更是人工智能、物联网、云计算等技术得以实现的基…

Docker 详解及详细配置讲解
Docker 简介 2008 年LXC(LinuX Contiainer)发布,但是没有行业标准,兼容性非常差 docker2013年首次发布,由Docker, Inc开发 什么是 Docker
Docker是管理容器的引擎,为应用打包、部署平台,而非单纯的虚拟化技术…
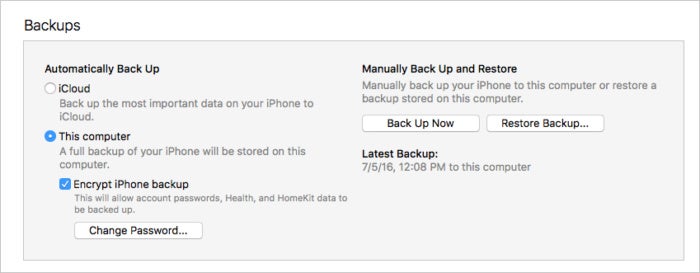
不小心删除丢失了所有短信?如何在 iPhone 上查找和恢复误删除的短信
不小心删除了一条短信,或者丢失了所有短信?希望还未破灭,下面介绍如何在 iPhone 上查找和恢复已删除的短信。
短信通常都是非正式和无关紧要的,但短信中可能包含非常重要的信息。因此,如果您删除了一些短信以清理 iPh…

Python画笔案例-032 绘制螺旋扇子
1、绘制螺旋扇子
通过 python 的turtle 库绘螺旋扇子图,如下图: 2、实现代码 绘制螺旋扇子,以下为实现代码:
"""螺旋扇子.py
"""
import turtle
from coloradd import * # 从coloradd命令导…

win12R2安装.NET Framework 3.5
一丶安装原因
因此插件的缺失, 有些软件或系统不支持安装.
二丶安装步骤
1丶下载.NET Framework 3.5 点击插件下载, 提取码: 1995, 下载完成之后解压到想要安装的位置上. 2丶打开 服务器管理器 3丶点击: 管理 -> 添加角色和功能 4丶点击下一步到服务器角色, 选择web服…
版本控制的核心:Git中的哈希与默克尔树解析
Git是最常用的代码版本控制工具。它帮助我们跟踪代码的更改、管理代码版本,同时保证代码库的完整性和安全性。我们知道 Git 中有一些基本的操作,比如commit、merge、rebase等,但这些操作的底层机制是如何实现的呢?哈希函数和默克尔…